Student Spotlight: Three Chameleon Projects Heading to SC'25
Bioacoustics, Snapshots, and AI: Student Innovations Pushing the Boundary of Science
- Sept. 30, 2025
This summer, three talented students used Chameleon to tackle challenges ranging from wildlife conservation to reproducibility and AI-assisted documentation. Their innovative work earned them spots at the ACM Student Research Competition at SC'25, where they'll present posters on autonomous bioacoustic monitoring, snapshot performance optimization, and intelligent documentation systems. Discover how Hudson Reynolds, Alex Tuecke, Zahra Temori, and Saieda Ali Zada leveraged Chameleon's infrastructure to create impactful solutions.
This month's user experiment blog highlights groundbreaking work by summer students on Chameleon. We're thrilled that their research will be showcased at SC'25 in November through three posters at the ACM Student Research Competition: Zahra Temori's work on snapshot optimization, Saieda Ali Zada's AI-powered documentation assistant, and Hudson Reynolds and Alex Tuecke's autonomous bioacoustic monitoring system.
Read on to discover how these students pushed the boundaries of cloud testbed capabilities.
Echoes of Earth

In this project, students Hudson Reynolds and Alex Tuecke tackled an interesting problem involving solar panels, highly-sensitive microphones, and bengal tigers (oh my!). The students worked on developing a prototype system for real-time, inexpensive, high-quality soundscaping at scale to provide natural resource managers with bioacoustic information for biodiversity conservation. They created two key components: "Listener," a solar-powered recording and streaming device built with ESP32 and AudioMoth, and "Aggregator," based on Raspberry Pi 5, which collects audio streams from multiple Listeners over WiFi HaLow and performs local inference using the Cornell BirdNET model to analyze recordings.
The students leveraged Chameleon's infrastructure extensively for their cloud backend. They hosted their Grafana Dashboard, Prometheus metrics time series database, and InfluxDB3 analysis database on a Chameleon Kernel-Based Virtual Machine (CHI@KVM) and used the Chameleon Object Store (CHI@TACC) for storing raw recordings. They also utilized CHI@EDGE infrastructure and Balena Cloud Fleets to facilitate scalability, maintainability, and organization of their distributed sensor network. This cloud-testbed integration enabled them to build a complete end-to-end solution that eliminates the need for manual data retrieval from field devices.
At the end of the summer, the students had accomplished an impressive feat: they demonstrated that their system could sustain 25 concurrent audio streams without falling behind, achieving 81% average CPU utilization on the Aggregator. They plan to deploy the system at organic vineyards in Michigan, where it will provide real-time bioacoustic monitoring. The system could help reduce operational costs compared to industry-standard Wildlife Acoustics devices (which cost $600-$1000+) by eliminating the need for manual retrieval and expert maintenance, making large-scale biodiversity monitoring feasible for land managers.
Link to poster: View Poster
Link to abstract: View Abstract
CC-Snapshot
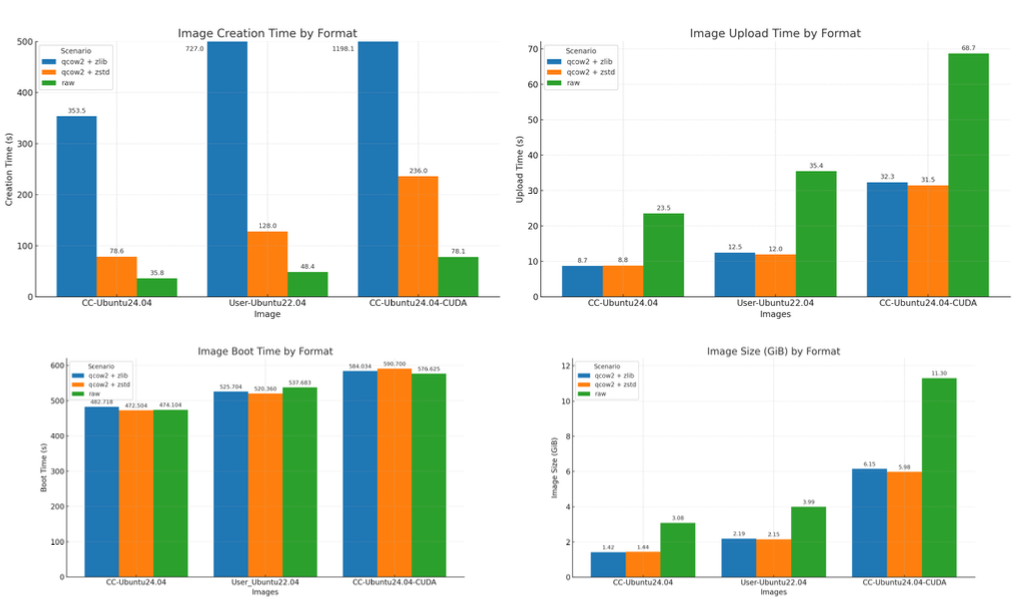
In this project, student Zahra Temori evaluated the CC-snapshot tool and set about implementing robust changes to improve the performance and usability. These changes were featured in our recent changelog! She worked on two main areas: enhancing usability and optimizing performance. For usability improvements, Zahra reorganized the tool's codebase into five modular functions, added new command-line flags (including dry-run mode and custom source path support), and implemented automated testing with GitHub Actions to ensure reliability.
Zahra used Chameleon's bare metal resources to conduct comprehensive performance benchmarking of the cc-snapshot tool. She tested different image formats (QCOW2 and RAW) and compression algorithms (zlib and zstd) on Chameleon nodes using three different image sizes (small 4.47 GiB, medium 7.62 GiB, and large 12.7 GiB). This benchmarking was essential because HPC experiments are resource-intensive and depend on complex software environments, making efficient snapshotting critical for reproducibility.
At the end of the summer, Zahra had accomplished significant performance improvements for the Chameleon community. Her benchmarking revealed that zstd compression reduced snapshot creation time by approximately 80% compared to the default zlib compression, while maintaining similar compression efficiency and upload/boot performance. These findings demonstrate that snapshotting can be a practical and effective tool to support reproducibility in HPC experiments, enabling researchers to generate and share reproducible environments much faster and improve research turnaround time.
Link to poster: View Poster
Link to abstract: View Abstract
Chameleon Concierge
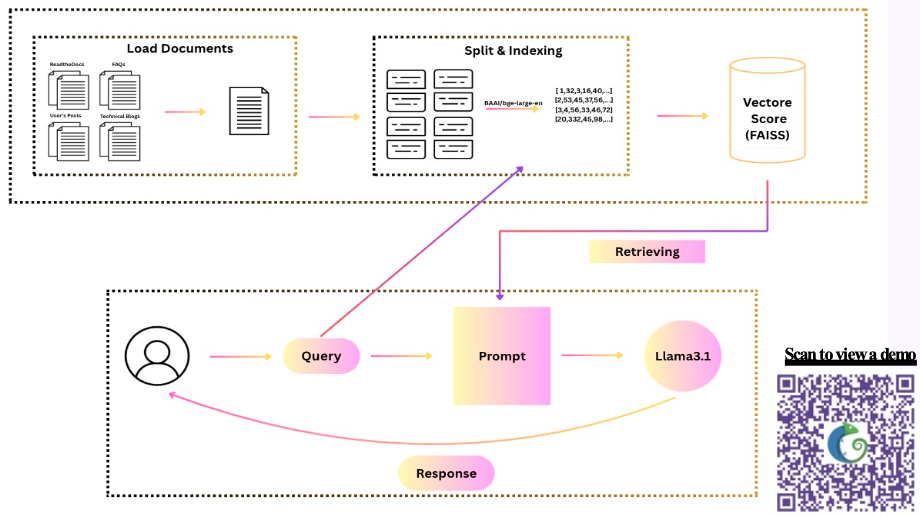
In this project, student Saieda Ali Zada innovated with LLMs, RAG systems, and Chameleon documentation, setting about to create a system that can respond to user queries automatically with sourced information from testbed official documents and internal documents (e.g., user tickets, and such). She worked on developing an AI-powered search system leveraging large language models with Retrieval-Augmented Generation (RAG) to unify various Chameleon documentation sources. The system collects information from Chameleon's ReadtheDocs website, FAQs, blogs, and public forum posts, processes them into searchable chunks, and uses semantic similarity search to retrieve relevant information. The system then uses Meta's Llama 3.1 model to generate accurate, context-aware answers with cited references.
Saieda leveraged Chameleon's computational resources throughout her development process. She conducted initial implementation work on the Perlmutter supercomputer, performed early development on an Apple M1 system, and ultimately deployed and evaluated the system on a KVM instance on Chameleon equipped with 1 NVIDIA H100 GPU (40GB). This GPU acceleration significantly reduced response latency from 10 minutes to just 20 seconds, making the system practical for real-time user assistance.
At the end of the summer, Saieda had accomplished a working RAG system (experimenting with over 14 iterations) that demonstrably outperforms generic LLMs (like base Llama 3.1) in answering Chameleon-specific questions. Through systematic evaluation using 20 test queries, she showed that her optimized models (particularly Models 7-14) won or tied against the negative baseline in 18-19 out of 20 comparisons. Her best-performing model (Model 12) even achieved performance comparable to proprietary models like OpenAI's GPT-5, winning 9 out of 20 head-to-head comparisons. This work demonstrates that well-designed open-source RAG systems can provide high-quality documentation assistance, potentially reducing the burden on support staff while improving the user experience.
Link to poster: View Poster
Link to abstract: View Abstract
These projects demonstrate the diverse capabilities of the Chameleon testbed—from supporting edge computing and real-time data processing to enabling large-scale performance benchmarking and GPU-accelerated AI workloads. The students' innovative approaches to real-world problems showcase how Chameleon empowers the next generation of researchers.
Join us at SC'25 in St. Louis this November to see these posters in person at the ACM Student Research Competition. Stop by to meet the students, learn more about their work, and discover what's possible with Chameleon. And don't miss Kate Keahey's presentation at the EduHPC workshop discussing our recent paper with Chameleon User Fraida Fund on her experiences and lessons learned from teaching a 200-student course on machine learning operations with the testbed in Spring 2025. She is hosting a webinar on this experience as well on Nov. 25th, 2025. Register here!
Chameleon Takes Flight at SC24: Advancing Research and Collaboration
Read on to see what we'll be up to during SC24 week! Nov. 17 to 20
- Nov. 19, 2024
Join Chameleon at SC24 in Atlanta from November 17-20, 2024, as we showcase our contributions to advancing high-performance computing research. From hands-on tutorials to a workshop on reproducibility, BoF sessions, and REU student presentations, we invite you to explore Chameleon’s role in driving innovation. Don’t miss our integration with SCinet and FABRIC, opening new collaboration opportunities. For more details or to connect with our team, visit us at SC24!
Chameleon presents AutoLearn, IndySCC'23 success, and more at SC'23
Chameleon talks, papers, posters, and more - all to be found at SC'23
- Nov. 10, 2023 by
- Marc Richardson
Attending SC’23? Check out the initiatives Chameleon is supporting at the event including workshops, papers written using Chameleon, and more! If you’re presenting something related to Chameleon at SC’23 and not on this list, send us an email – we will update this announcement with relevant information as we get it.
Chameleon at SC '23
- Oct. 13, 2023
We would like to congratulate Alicia Esquivel Morel and the team for the acceptance of their paper, AutoLearn: Learning in the Edge to Cloud Continuum, to the SC '23 conference as well as two summer REU students who had posters accepted to SC.
No comments