Real-time Scheduling for Time-Sensitive Networking: A Systematic Review and Experimental Study
Optimizing Network Performance with Chameleon's Computing Power
- June 25, 2024 by
- Chuanyu Xue
Imagine a world where every device in your home required its own unique network to communicate. Your living room would be a tangled mess of wires, and the cost of maintaining these separate networks would be astronomical.


This scenario reflects the challenge faced by many industries today, where different types of communication, each with their own safety requirements, demand separate networks. For example, sensor data might use serial communication, motion control relies on CAN-bus, high-resolution video cameras require Ethernet, and safety operations need yet another network. While this approach ensures safety and reliability, it also significantly increases system complexity and cost, making maintenance a nightmare. If you've ever seen the communication system within an aircraft at NASA, you'll understand the scale of the problem—countless wires for each subsystem, all in the name of safety.

To address this issue, Time-Sensitive Networking (TSN) was developed. TSN is a set of standards built upon Ethernet, developed by the IEEE 802.1 working group to address the challenges of mixed critical communication within a single network. It defines traffic shaping and scheduling techniques to support different levels of communication, ensuring that data with varying importance and timing requirements can coexist on the same network without causing congestion or delays. TSN also supports features like network-wide synchronization, stream reservation, and redundancy for uninterrupted communication. However, configuring TSN networks for specific use cases remains a challenge. This is where my research comes in, aiming to create a benchmark for systematically understanding and comparing existing TSN scheduling methods.
Research Overview:
My study makes three key contributions. First, I propose a model-based categorization to compare approaches used by each scheduling method. Second, I set up a physical testbed for hardware validation. Finally, I create a comprehensive benchmark considering relevance, fairness, and reproducibility. For this last part, I rely on Chameleon to conduct large-scale experiments on online computing platforms.
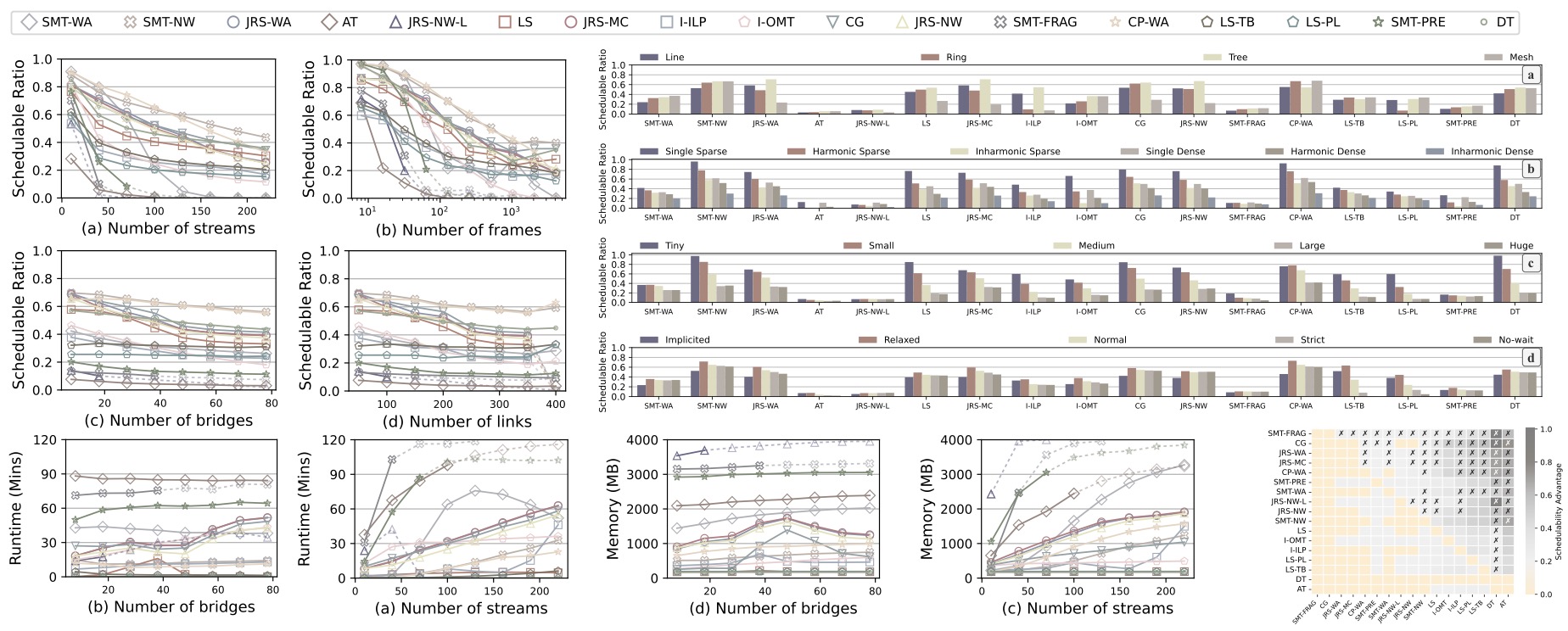
High-level preview of the large-scale experiment results based on Chameleon
Key Findings:
Using Chameleon, I conducted comprehensive evaluation experiments on 17 scheduling algorithms across 38,400 problem instances with two evaluation metrics. I'll discuss two major findings here, while more details can be found in my paper.
First, using different evaluation metrics can yield inconsistent comparison results, suggesting the need for diverse metrics to better understand the pros and cons of algorithms. Second, schedulability varies under different settings, even when using the same evaluation metric, highlighting the importance of comprehensive experiment settings to avoid bias. These findings should help the community better understand existing TSN scheduling methods and provide insights for future development.
Experiment Implementation on Chameleon:
My experiments involve solving optimization problems using third-party mathematical solvers and self-implemented algorithms in Python. These tasks are CPU and memory-intensive, and I faced three main challenges during implementation.
The first challenge was managing many computing servers effectively. I allocated 16 compute_zen3 nodes, each with 2 AMD EPYC® CPUs (64 cores per CPU, 2.45 GHz) and 256 GB DDR4 memory. I used the bare metal model and SSH for connections. A useful tip I discovered is to configure a single node, save its system image with the cc-snapshot utility, and then boot other nodes using this image. For code synchronization, I used GitHub to pull the latest code to the Chameleon nodes. Another tip is configuring the same RSA key on different nodes allows for a single SSH key configuration on GitHub.
The second challenge was conducting experiments efficiently. With 17 scheduling methods and 38,400 problem instances, I needed to run over 650,000 experiments. To reduce runtime, I developed a strategy for parallel execution on multi-core processors using Python's multiprocessing library. I employed the longest-processing-time-first strategy within single nodes and balanced workload across multiple nodes based on estimated runtimes.
The final challenge was collecting results. I used SSH to download data at more than 1Gb speed, thanks to Chameleon's high-speed network. A useful tip is to use a script to download results in real-time instead of waiting for the experiment to finish, preventing data loss due to expired leases.
Chameleon Features Utilized:
The features of Chameleon crucial for my experiment include large amounts of computational resources with consistent node performance, the bare-metal model for customized resource management, SSH that supports full speed data exchange, and custom kernel boot for convenient configuration. The bare-metal reconfiguration was particularly useful as it allowed me to have full control over the environment.
If Chameleon wasn't available, it would have significantly impacted my experiment. The scale of computational resources and the flexibility to configure them according to my needs would be hard to find elsewhere. It might have been possible to carry out the experiment on a smaller scale, but it would have been much harder and time-consuming, potentially affecting the comprehensiveness of my results.
Experiment Artifacts:
For those interested in delving deeper into my research, you can find my paper titled "Real-Time Scheduling for 802.1Qbv Time-Sensitive Networking (TSN): A Systematic Review and Experimental Study" on arXiv. The source code for my project is available on GitHub under the repository name "tsnkit: A scheduling and benchmark toolkit for Time-Sensitive Networking in Python".
User Interview
About Me:
I'm a fifth-year PhD student at the University of Connecticut, working in the cyber-physical lab. My research focuses on real-time systems and their applications in time-sensitive networking. In the future, I want to find an R&D job position about computer systems in industry. I primarily use C/C++, Python, and GoLang for my work. Additionally, I'm independently developing iOS/macOS applications using SwiftUI.
In my free time, I enjoy reading, cycling, veggie planting, and coffee brewing. Here's an interesting tidbit about me: I was previously an independent musician in China, where my music earned over 247k listens online!
Advice for Aspiring Researchers:
If I could offer one piece of advice to students beginning research, it would be this: find a research style that you enjoy. Computer science research allows for different approaches, from solving problems through real implementation to working with mathematical abstractions or conducting experiment-based research. Each style has its own advantages and is suited to solving different problems. The important thing is to discover which style you are most interested in and better suited for, and then dedicate time to learning and working in that area.
Staying Motivated:
To me, the most helpful insight for staying motivated is to recognize that PhD progress is more like an area (integral) than a height. If we plot our progress, the horizontal axis represents time, and the vertical axis represents our progress at each moment. The total progress we make isn't determined by where we are right now, but by the area covered under the entire line segment.
When we feel frustrated, we should remember that we can't measure our entire Ph.D. life by our current state. It depends on whether we have consistent reading, coding, writing, and thinking over the long term. This perspective helps me stay motivated even during challenging times, knowing that consistent effort over time is what truly matters.
In conclusion, my research on TSN scheduling methods, facilitated by the powerful resources of Chameleon, has provided valuable insights into the field. It's my hope that this work will contribute to more efficient and reliable network configurations in various industries, potentially reducing the complexity and cost of communication systems. As I continue my journey in computer science research, I look forward to tackling more challenges and making further contributions to this exciting field.
Thank you for sharing your knowledge with the Chameleon community!
Using Paramiko to Tune Network Performance
- Aug. 16, 2021 by
- Mason Hicks
Interested in large-scale networking research? Learn more about GENI-style stitching and how to optimize host tuning for 20x performance increases with Python's paramiko package. This blog complements a fully packaged experiment on Trovi, so you can practice doing this yourself! New to Trovi? This blog also outlines how to start running the notebook on Trovi.
Managing Multiple External Links Stitched to a Single Chameleon Network
- Aug. 31, 2020 by
- Paul Ruth
We have created and shared a new Jupyter notebook that shows a better way to combine standard isolated Chameleon networks with DirectStitch capabilities. This more advanced method shows how to separate management of the stitched links from the compute nodes.
Isolating Wide-area Networking and Distributed Computing Experiments
- June 21, 2019 by
- Paul Ruth
Chameleon's DirectStitch capabilities enable isolated direct OSI layer 2 connections between tenant networks and external facilities, including other Chameleon sites.
No comments