Optimizing Production ML Inference for Accuracy and Cost Efficiency
Pushing the Boundaries of Cost-Effective ML Inference on Chameleon Testbed
- May 28, 2024 by
- Saeid Ghafouri
Over the past decade, advancements in machine learning (ML) have paved the way for numerous real-world use cases such as chatbots, self-driving cars, and recommender systems. Traditional ML applications typically use a single deep neural network (DNN) to perform inference tasks, such as object recognition or natural language understanding. In contrast, modern ML systems – those used in sophisticated systems (think digital assistant services such as Amazon Alexa) – are very complex. These systems employ a series of interconnected DNNs, often structured as directed acyclic graphs (DAGs), to handle a variety of inference tasks, including speech recognition, question interpretation, question answering, and text-to-speech conversion, all working together to meet user queries and requirements.
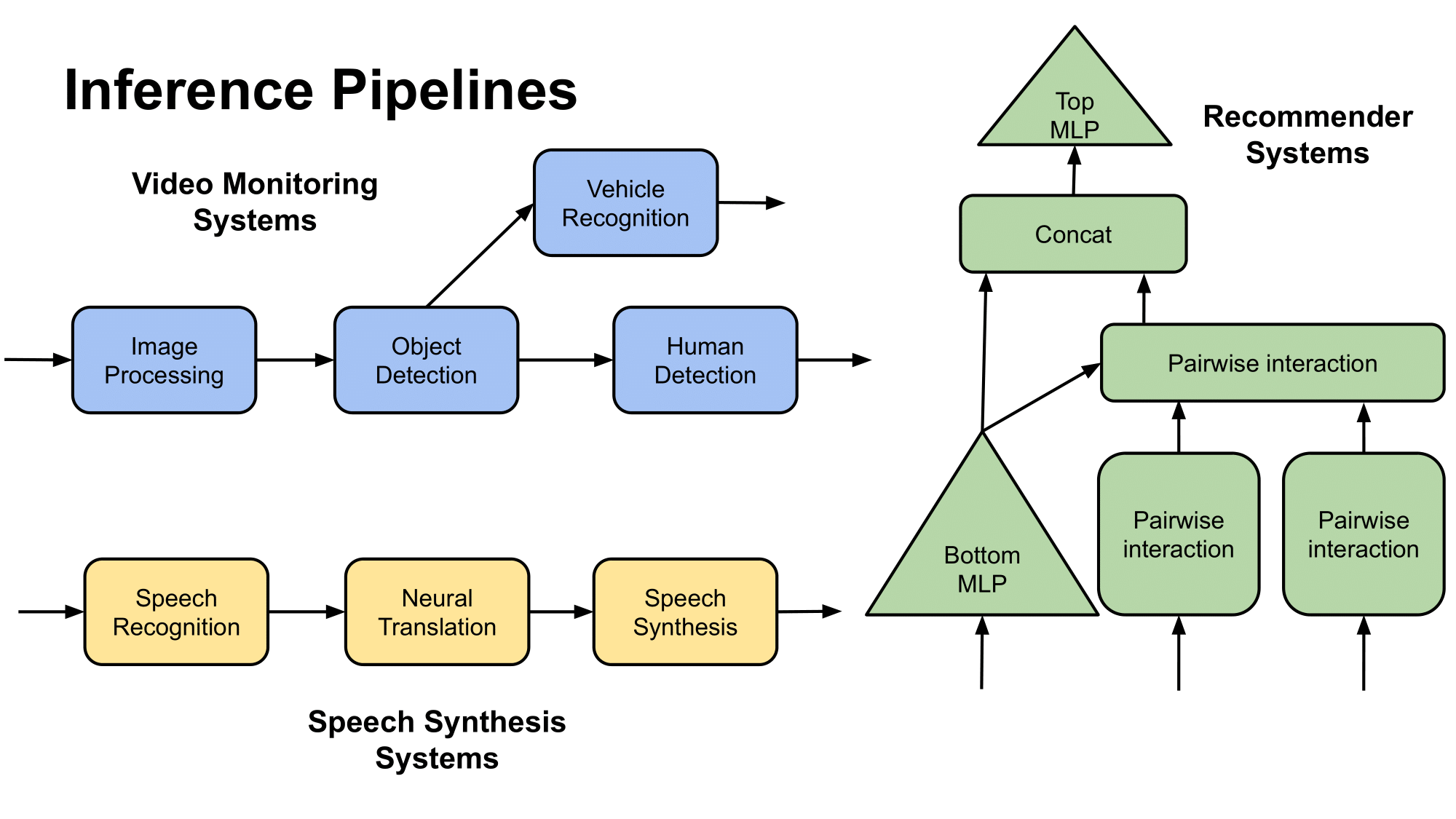
Inference pipelines are composed of several inference tasks
ML inference pipelines, consisting of a series of ML models, present several challenges for performance optimization in the presence of real-world cost constraints. Achieving high accuracy often requires complex models, extensive data, and significant computational resources, which increase costs. Conversely, simpler models with lower data and computational demands are less costly but typically offer reduced accuracy. Operators of ML systems must reckon with a trade-off between prediction accuracy and cost minimization. What is the optimal balance to provide high predictive accuracy while accounting for the operator’s budget constraints, goals, and resources?
Utilizing ML in real-world scenarios requires a new deployment infrastructure designed to accommodate those competing requirements. The current infrastructure used to deploy ML systems, which involves using containerized services on top of frameworks like Kubernetes or Docker, makes it easier to package and deploy models, ensuring consistent performance and reliability throughout development and production. Yet, existing cost management solutions available on current infrastructure are general-purpose solutions that do not address the accuracy/cost optimization problem present in ML systems. There is thus an opportunity for new infrastructure that can handle complex requirements while remaining cost-effective.
Research Findings
The central hypothesis that our experiments investigated was: "Can we optimize ML systems to achieve high accuracy while significantly reducing costs, particularly in scenarios involving multi-variant and multi-stage inference graphs?" Balancing the conflicting objectives of accuracy and cost was a significant challenge, particularly when dealing with multiple models, each with its unique computational requirements and performance metrics.
To tackle this, we – a collaboration of researchers at the Queen Mary University of London, University of South Carolina, Technische Universität Darmstadt, and Roblox – focused on optimizing inference systems by selecting model variants based on specific system needs, prioritizing either accuracy or cost-effectiveness as required. This flexibility allowed us to design three systems – InfAdapter, IPA, and Sponge – that demonstrate how to achieve high accuracy and cost efficiency in ML applications. We explain each system below and how they contribute to making advanced ML technologies accessible for a wide range of real-world uses.
InfAdapter tackles the issue of dynamic workloads and the need for fast, accurate responses in ML inference services. It proactively selects a set of ML model variants and their resource allocations to meet latency Service Level Agreements (SLAs) while maximizing an objective function composed of accuracy and cost. (Latency SLA is crucial in ML services because it ensures timely responses, maintaining user satisfaction and system reliability.) This system adapts to workload changes, reducing SLO violations and lowering costs by up to 65% and 33%, respectively, compared to traditional autoscalers like the Kubernetes Vertical Pod Autoscaler.
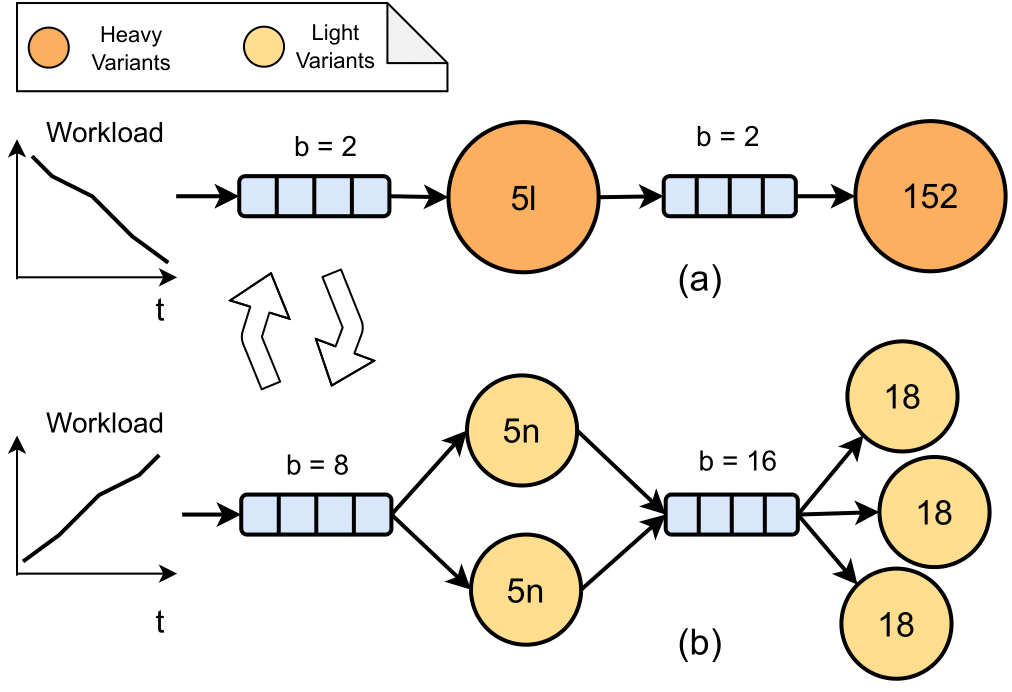
IPA can dynamically switch between different configurations in terms of batch size, scale, and model variants.
IPA focuses on optimizing multi-model inference pipelines, crucial for fast, accurate, and cost-effective inference in production systems with stringent end-to-end latency requirements. IPA dynamically configures batch sizes, replication, and model selection to balance accuracy, cost, and latency, leveraging a variety of pre-trained model variants for each task. IPA models the intricate relationship between these factors using linear integer programming (ILP), a mathematical optimization approach that deals with problems where variables must be integers and relationships are expressed as linear equations or inequalities. ILP is particularly suitable for this context because it can efficiently handle the discrete nature of model selection and configuration decisions, while simultaneously optimizing multiple competing objectives. By using ILP, IPA achieves better trade-offs between these objectives than existing methods, improving end-to-end accuracy by up to 21% with minimal cost increases.
Sponge addresses the unique challenges of mobile and IoT applications by maximizing resource efficiency while guaranteeing dynamic SLOs at the request level. It employs in-place vertical scaling, dynamic batching, and request reordering to adapt to highly variable wireless network conditions. Sponge formulates the resource allocation problem with ILP to optimize the relationship between latency, batch size, and resources, maintaining high performance and efficiency in dynamic, resource-constrained environments.
These systems collectively demonstrate that high accuracy and cost efficiency in ML applications are achievable through dynamic adaptation and optimized resource allocation, providing scalable and practical solutions for real-world scenarios.
Running the Experiments on Chameleon
Chameleon’s different resource flavors, like bare metal and VMs, gave us flexibility in our system design decision. We primarily utilized bare metal machines available at UC and TACC to build our infrastructure from scratch without the need to deal with any platform-specific solutions. For smaller modules, we also employed VMs on KVM. All three systems were implemented on the widely recognized container orchestration framework, Kubernetes. We set up Kubernetes clusters with two nodes for InfAdapter, six nodes for IPA, and one node for Sponge. Additionally, we prepared the Kubernetes infrastructure to be deployment-ready for ML services. Each system was designed to bring up ML production inference services on top of the cluster we created on Chameleon. To support our experiments, we developed a suite of tools including monitoring solutions, load-testing utilities, and customized autoscalers.
One of the standout features of Chameleon is its high configurability through its bare metal capabilities. Given the nature of our research, we needed to construct a Kubernetes cluster from scratch with numerous modifications to build our systems effectively. Most computational resources in academic institutions have restricted access privileges and are typically accessible only through tools like Slurm, which made conducting our experiments on them impractical. The main advantage of using Chameleon for our research was the ability to lease bare metal machines and build our experimental testbed from the ground up, providing us with the flexibility and control required for our customized Kubernetes deployment.
Experiment Artifacts
All three papers are now accessible: InfAdapter and Sponge were published in the 3rd and 4th EuroMLSys workshops associated with EuroSys. IPA is now published in the Journal of System Research.
All the project codes are also publicly available with set-up instructions for running the experiment on Chameleon. IPA has also been reproduced by the JSys artifact evaluation board.
User Interview

Tell us a little bit about yourself
I recently started a postdoctoral position at Queen’s University Belfast, where I continue to focus on optimizing ML inference. Prior to this, I completed my PhD at Queen Mary University of London, concentrating on making ML systems more cost-efficient and optimizing cloud services using reinforcement learning. During my PhD, I spent a year as a visiting researcher at the University of South Carolina’s AISys lab, where I began using Chameleon for my projects. My work was supported via NSF grants (Awards 2107463 & 2233873). My research interests revolve around making cloud and edge environments suitable for deploying ML systems. In the future, I aim to pursue my interests at the intersection of computer systems and ML, whether in academia or industry.
When I’m not thinking about ML inference, I enjoy watching movies, running, and swimming. I also love to travel and explore different places and cultures.
Most powerful piece of advice for students beginning research or finding a new research project?
Good research takes time, and there is also an element of luck in discovering a compelling research problem. Some people find a great problem in the first year of their PhD, while others do their best work toward the end. Push yourself to find exciting new problems, but don’t stress if it takes a while to identify the right one. For system researchers, given the practical nature of the field, I recommend always engaging with real-world cases and connecting with industry professionals. Often, they have interesting problems that need motivated students to solve them.
How do you stay motivated through a long research project?
I prioritize selecting a research topic aligned with my interests and passions, as it will be my focus for an extended period, often at least a year. Because in system research most works takes at least a year and any topic I choose will be my work for a year. Therefore, I try to find something motivating enough for myself from day one. Other than that, I try to collaborate with people that I know can add value to my work and I know I can learn from them. Also, although as a researcher we need to reach certain deadlines, I try to make my research more about the topic I’m learning rather than only focusing on reaching a conference deadline.
Why did you choose this direction of research?
I chose to focus my research on optimizing cost-efficient ML (ML) inference for a few important reasons. Firstly, ML inference involves balancing computing resources to save money while keeping performance strong. Secondly, as ML models get bigger, they can become very expensive to run. By finding ways to save money, we can make ML more accessible to more people. Lastly, companies really want cost-effective ML solutions because they want to spend less money on running their models. So, my research directly helps them while also making ML better and more accessible for everyone.
Thank you for sharing your knowledge with the Chameleon community!
Baleen: ML Admission & Prefetching for Flash Caches
Future-Proofing Data Storage: The Role of ML in Smart Caching Solutions
- March 26, 2024 by
- Daniel Wong
In the era of exponential data growth, the "Baleen" project introduces a groundbreaking approach to flash caching, utilizing machine learning to optimize data storage. This method intelligently decides what to store and prefetch, significantly reducing the hardware required, lowering costs, and enhancing sustainability. This blog explores the challenges of managing vast data volumes and how "Baleen" offers a novel solution, poised to revolutionize data center operations and sustainability practices.
Automated Fast-flux Detection using Machine Learning and Genetic Algorithms
- May 23, 2022 by
- Ahmet Aksoy
Interested in protecting remote devices from malicious actors? Learn about how a researcher at the University of Missouri is approaching this problem with genetic algorithms and host fingerprinting! Also included is a YouTube video where Dr. Aksoy discusses this research.
No comments