Automated Fast-flux Detection using Machine Learning and Genetic Algorithms
- May 23, 2022 by
- Ahmet Aksoy
Interested in protecting remote devices from malicious actors? Learn about how a researcher at the University of Missouri is approaching this problem with genetic algorithms and host fingerprinting! Also included is a YouTube video where Dr. Aksoy discusses this research.
What is the central challenge your experiment investigates?
Host fingerprinting is a technique to identify remote devices based on their behavior at hardware and/or software level. We analyze the header information of the packets generated by hosts to capture the uniqueness in their values which allow us to perform fingerprinting. With the ability to identify hosts based on their unique characteristics, we can identify and isolate traffic generated by malicious hosts. Fast-flux is a technique employed by malicious bots to hide their origin by rapidly changing DNS entries. Although specific features in DNS protocol fields are known to help detect malicious hosts, attackers are becoming more knowledgeable and can spoof these values to make the infected hosts resilient to detection. Therefore, there arises the need for an approach which can detect such changes in malicious hosts’ behavior automatically so that it would be possible to identify malicious traffic regardless of attackers’ attempt to hide their tracks.
How is your research addressing this challenge?
We present an entirely automated fast-flux detection approach using machine learning and evolutionary algorithms such as genetic algorithms that helps us perform classification without expert input. The presented approach makes fast-flux detection insusceptible to changes in infected hosts if a representative dataset is provided, making it more difficult for attackers to hide their hosts. Our approach was able to achieve more than 99% accuracy in classifying benign and malicious hosts.
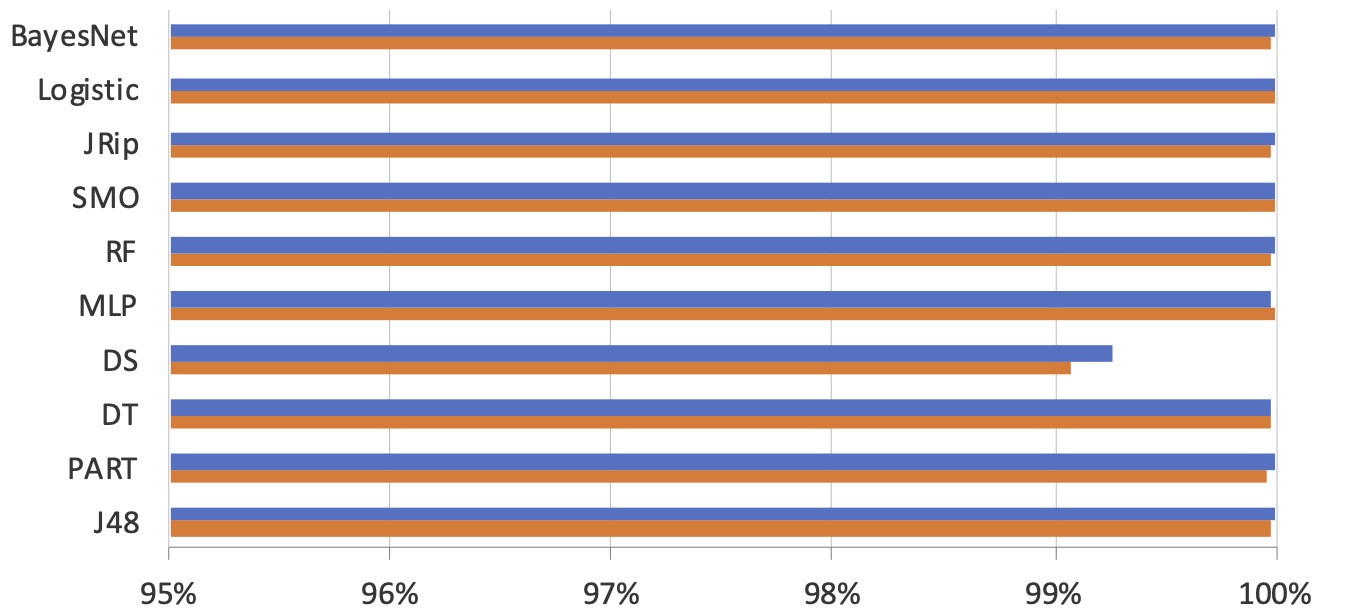
Figure 1: Classification accuracy (Blue: w/out GA, Orange: w/ GA)
How do you structure your experiment on Chameleon?
In our research, we use computationally expensive algorithms such as Genetic Algorithms (GA) for feature selection. In GA, we test each potential solution’s contribution to our classification problem by running a fitness function. Fitness function typically returns a value, in our case between 0 and 100, indicating how much contribution the potential solution makes to our problem. During my Ph.D., I coded a program in Java which performs Operating System and IoT classification using Genetic Algorithms and Machine Learning. I had coded my program to be able to run in multiple threads. For instance, with a population size of 50, we need to run the fitness function on 50 potential solutions at a time and therefore, I assign each potential solution to a thread and calculate their fitness value. Chameleon servers had been a tremendous help for me to automate this process and to be able to obtain results much faster. The ability to create multiple servers also helped us distribute the workload. My code runs completely on the command line environment.
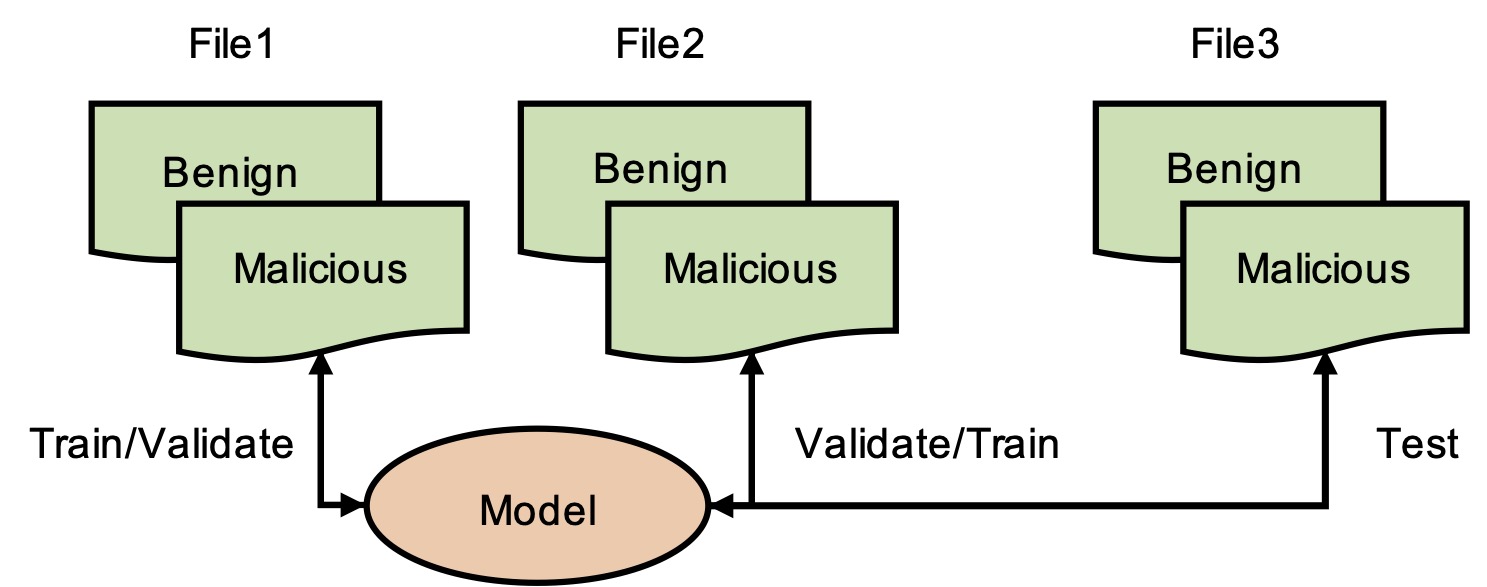
Figure 2: Classifiers
What features of the testbed do you need in order to implement your experiment?
I coded the tool used in our research in JAVA along with WEKA libraries for machine learning classification. In order to benefit from the hardware provided in Chameleon services, I implemented our tool in multi-thread to utilize the processing power. I merely used the command line environment to conduct our research. I also wrote bash scripts to automate the process for various protocols for which we tested our approach’s accuracy. The ability to create numerous servers in the Chameleon environment has helped us immensely in order to reduce the processing time. It would’ve been very difficult to collect results in a reasonable amount of time if we hadn’t used a platform like Chameleon.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
Link to my presentation video at the conference: https://www.youtube.com/watch?v=OEKEoWWQdkk

Photo courtesy of the author
About the Author
My name is Ahmet Aksoy. I completed my Ph.D. at the University of Nevada, Reno in 2019. My thesis was on Network Traffic Fingerprinting using Machine Learning and Evolutionary Computing.
After my graduation, I started working at the University of Central Missouri as an assistant professor at the Cybersecurity department. I’m currently working at the same institution.
My research interests include Cybersecurity (including Network Security, Anomaly Detection and Intrusion Detection), Network Traffic Fingerprinting (including Operating System Identification, IoT Device Classification and User Fingerprinting), Machine Learning (including Inductive learning, Deep Learning and Rule-based Classifiers) and Evolutionary Computing (including Genetic Algorithms).
In the future, I would like to proceed with my research and develop new ideas for automated network traffic fingerprinting for the detection of malicious and unauthenticated hosts, users, software and devices. I’m currently working with 10 graduate students on several research papers to help me reach my goals. Research is one of my passions and I would like to continue to contribute to the community with new ideas and solutions.
In my spare time, I enjoy traveling (I'm quite a wanderlust), playing some keyboard, going to concerts and playing table tennis.
How do you stay motivated through a long research project?
I make sure to keep a balance between my work and my life. I believe it is very important to find hobbies that would help decompress from stressful times. Also, the sense of productivity is one of the biggest motivators for me.
Are there any researchers you admire? Can you describe why?
My father, Dr. Mehmet Sabih Aksoy, has always been a role model for me. My second role model has been my Ph.D. advisor, Dr. Mehmet Hadi Gunes. I have received invaluable experience and knowledge about research from my advisor. I have also admired Dr. Ross Quinlan for his contributions to the field of Inductive Learning. His algorithms such as ID3, C4.5 and C5.0 have been a motivating factor not only to me but also to many researchers for developing ideas in the Machine Learning field.
Why did you choose this direction of research?
My father, Dr. Mehmet Sabih Aksoy, is a professor in the field of Machine Learning. His research has always been inspiring to me from the very early ages. He also used to take me to his office frequently during his Ph.D. studies which I believe is one of the reasons why I feel at peace in a University environment. My father had developed several inductive learning algorithms during his Ph.D. studies. I had always been fascinated with how computers would learn from data and make decisions ever since I was in middle school. This was one of the first motivations to direct me to the field of Machine Learning as one of my research areas.
No comments