Baleen: ML Admission & Prefetching for Flash Caches
Future-Proofing Data Storage: The Role of ML in Smart Caching Solutions
- March 26, 2024 by
- Daniel Wong
Much of the world’s data lives in data centers belonging to large internet companies. Some estimate that the total amount of data in the world is over 64 zettabytes, with approximately 328.77 million terabytes created each day. The International Data Corporation estimates that the global data volume will expand to 175 zettabytes by 2025. How is all that data to be stored?
Many companies managing lots of data, like Google and Meta, use specialized systems called bulk storage systems, and rely on hard disks to store data cheaply. But hard disks have insufficient bandwidth to handle real-time user demand, so these systems also depend on fast flash drives to cache popular items. (A cache is a smaller and faster storage placed in front of a larger and slower backend storage.) Better caching means fewer hard drives are needed.
However, flash drives have limited lifetime writes. Without a smart policy to control what gets written, they might need to be replaced every 4 months. As the volume of data continues to grow, we need to design smart flash caching policies that optimize both flash writes and hard disk load reduction, minimizing the number of flash drives and hard disks needed to maintain storage systems and extending hardware lifespan, a boon to sustainable computing.
Our Research Findings
Baleen is a smart flash cache that uses machine learning (ML) to solve the flash admission problem (i.e., deciding what should be written to the flash cache) and prefetching (i.e., deciding what data can be fetched now to reduce load later). It does this in a novel way by using our proposed episodes model to train the ML policies.
A personal computer uses the file path to know where to find the file on the local disk. A bulk storage system stores fixed-size blocks instead (8MB is common) and uses a Block ID to know which server to locate the data on. Different applications (such as data warehouses and blob stores) access the bulk storage system over time, and we illustrate accesses to different blocks over time in Figure 1.

Figure 1: Admission decisions are made on misses.
The flash cache is faster but also smaller than the hard disk backend - not everything can be stored in it. On each application access, the bulk storage system checks if the flash cache contains the data needed for the request. If it is present, we call that a hit, which reduces hard disk load. If the data is absent, we call that a miss, and the system must fetch the data from the hard disk.
The problem of flash caching is deciding which pieces of data should be stored in the flash cache in order to minimize the hard disk’s load. On each miss, an admission policy is called to decide if the data should be admitted, i.e., stored in the flash cache.
Our policy, Baleen, is trained using ML and uses features such as metadata about the requesting application and the number of times the block was accessed in the last 6 hours to make this admission decision.
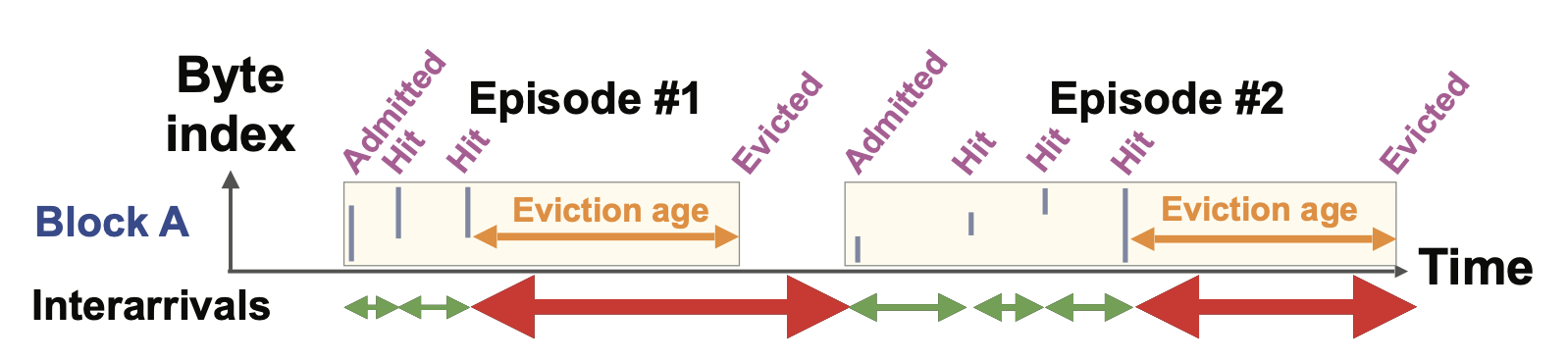
Figure 2: Episodes are generated by grouping accesses temporally from admission to eviction.
Episodes are a cache residency model that groups accesses temporally from admission to eviction (Figure 2). Episodes are generated by looking at interarrival times (the time between consecutive accesses to the same block); each episode ends when the interarrival time exceeds the cache’s average eviction age (the time between the last access to a block and its eviction or removal from the cache). We use this model to train Baleen. The advantage is that the policy can deal with fewer, independent episodes instead of many interdependent accesses, allowing for efficient divide-and-conquer approaches and focusing on the critical decision points.
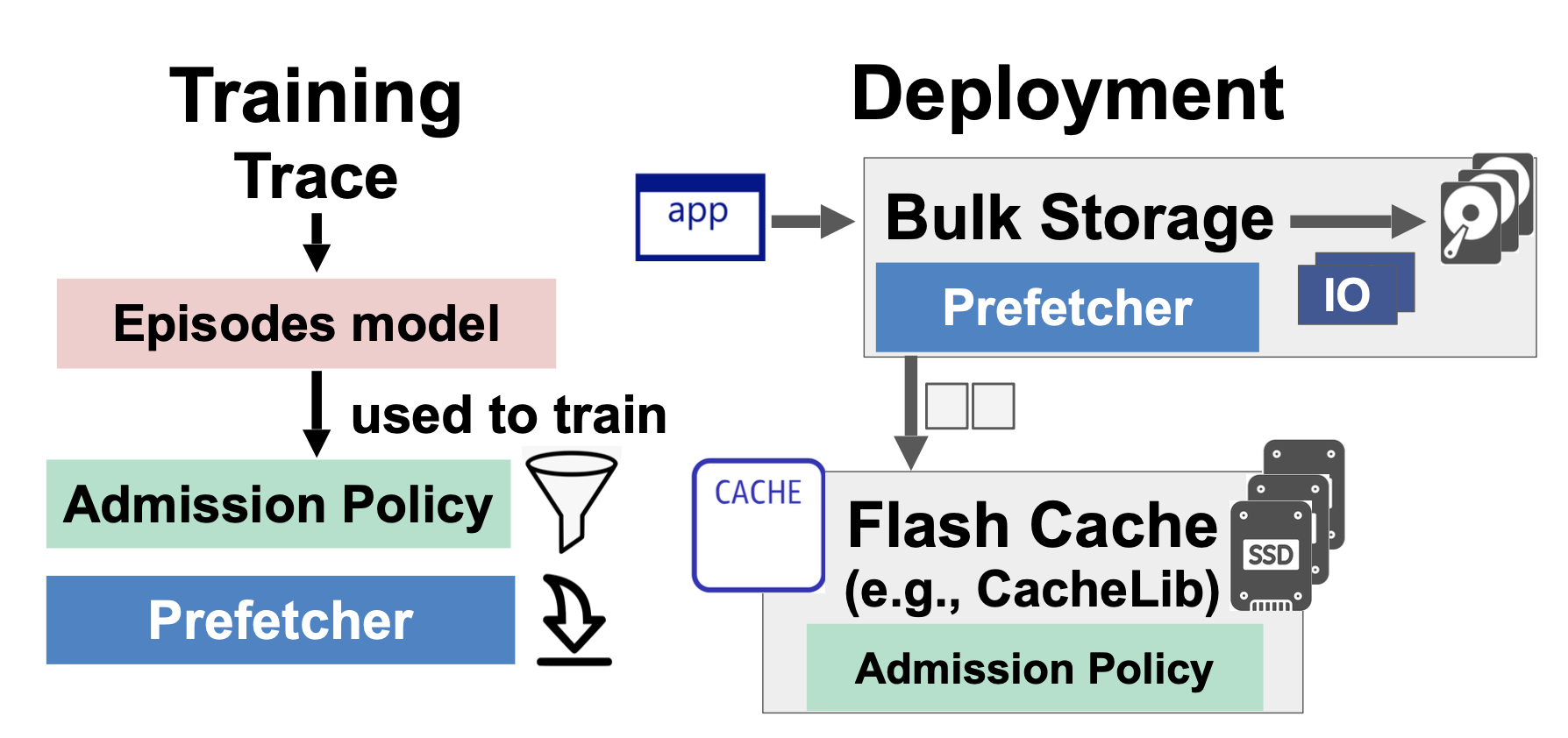
Figure 3: Architecture. An admission policy in CacheLib decides whether to admit items into flash. Prefetching (preloading of data beyond the current request) takes place in the bulk storage system.
As shown in Figure 3, the ML models are trained offline on a trace and then supplied to either the Python simulator or CacheLib (not included in the artifact), which replays our traces from Meta’s bulk storage system, Tectonic.
By training smart ML admission and prefetching on episodes, we can reduce system load and thus cost. In simulations and testbed evaluations on real Meta traces, we reduced estimated storage costs by 17% (by reducing the number of hard disks and flash drives required).
Running the Experiment on Chameleon
I used Chameleon to host our experiment artifact for a paper that we submitted to the FAST 2024 conference. The scope of the artifact included running selected experiments on our Python simulator and reproducing graphs using an intermediate results file and Jupyter notebooks we supplied.
I recommend using Trovi’s functionality to clone from a Git repository, so that you can include Chameleon-specific scripts inside your existing Git repository. While the packaging ability available via the shared JupyterHub is convenient, I found it advantageous to manage one versioning system instead of two.
As I needed more computing resources than the shared JupyterHub server could support, I used a JupyterHub server to first provision a single beefier machine on which I then ran Jupyter. I found the Trovi artifact catalogue very useful, as I was able to find an existing application (Basic Jupyter Server) to adapt. I recommend looking at it to find similar experiments and adopt best practices.
Our experiment reviewers were able to use Chameleon to launch their own Jupyter server, run a simulation and reproduce graphs found in our paper. Chameleon and Trovi enabled our reviewers to easily set up the required environment with the correct dependencies, and made it easier for them to focus on the research itself. Without Chameleon, supporting the varied environments on reviewers’ personal machines would have been much more challenging. Originally, we offered the self-installation option but this gave rise to many reviewer-specific installation issues; we later asked our reviewers to use only Chameleon as it was the most straightforward way of reproducing our results.
Experiment Artifacts
Our paper, code, and traces can be accessed here. Our GitHub repository for our artifact contains code necessary to reproduce our results, our simulator code, Chameleon scripts, and a README.
We have also produced a video walk-through showing results being reproduced on Chameleon.
You can find the Trovi artifact (which is also linked to in the README) on Chameleon here.
Our artifact was evaluated by the FAST ‘24 Artifact Evaluation committee and awarded all 3 badges: Artifact Available, Artifacts Functional and Results Reproduced.
User Interview

Tell us a little bit about yourself.
I am a PhD student at Carnegie Mellon University, and as a 7th-year student, I am on the job market for industry positions in engineering or research (my website). At CMU, I am a member of the Parallel Data Laboratory and the Computer Science Department. My research interests are ML + Systems (ML for Systems & Systems for ML), distributed systems, and scalable systems. Outside of work, I enjoy nature and cooking (especially edomae sushi). I hail from Singapore and did my undergraduate studies at the University of Cambridge in the United Kingdom.
Most powerful piece of advice for students beginning research or finding a new research project?
In my first two weeks at CMU, a senior professor gave me this piece of advice: a successful graduate student is good at breaking down their research into week-size chunks and at producing something each week to get feedback from their advisor, even if it means your initial experiments are simplified and far from rigorous. This advice has aged well - I would add that making the right approximations is a skill you hone during your PhD. To sum it up, done is better than perfect.
The advice I would give to my younger self is: worry less about the research problem and how popular you think it is. You'll always be behind the curve if you try to follow trends. More important is to make progress and get something out there, even if it's imperfect or not what you want to be known for. The connections that you gain as you present your research are just as important, and the feedback will help you in your next project. You won't know what will be immediately useful - but if you learn something properly, it will come back to help you in the long run (it might even be 2 or even 10 years later). I'm always amazed at how the dots connect, looking back.
How do you stay motivated through a long research project?
The first order of business is to realize that progress in research comes in spurts, and failure is par for the course. The second most important thing is that your sense of purpose in life and self-worth should not be defined by your research progress. It is easier said than done to disentangle your personal happiness from your research. Having friends and loved ones to accompany you through your PhD journey is important. Maintaining good relationships with people, including your collaborators, is important, as is recognizing that failures in research do not (necessarily) mean that you have failed your collaborators. It is important to remember that tough times don’t last. Practically, many PhD students, including myself, find it helpful to keep hobbies that give you the satisfaction of progress from small steps; some people do rock climbing, some do pottery, some cook, and so on.
What factors do you think contribute to a successful research publication?
I realized recently how critical timing can be to a successful research outcome. Identifying a good problem is important, but not sufficient. As a junior student, one of my early projects failed because I did not have the technical ability at the time to execute the solution. Another project was stalled due to a lack of real datasets. It is important to recognize our limitations and play to our strengths in picking an appropriate problem.
Having the right collaborators for your project is also critical. Each conference has its insiders who are familiar with the expectations for acceptance. Moreover, choosing the right venue for your work is important. One conference’s best paper may be rejected at another, because different fields have different preferences. It is also important to communicate and sell people on your work - and that can take years, but you can start with your fellow students, one student at a time.
It is always important to treasure our opportunities at each point in time.
Thank you for sharing your knowledge with the Chameleon community!
Metis Unleashed: A New Dawn for File System Integrity
- Feb. 27, 2024 by
- Yifei Liu
File systems are a fundamental part of computer systems, which organize and protect the files and data on assorted devices, including computers, smartphones, and enterprise servers. Due to its crucial role, vulnerabilities and bugs in the file system can lead to severe consequences such as data loss and system crashes. After decades of development, file systems have become increasingly complex, yet bugs continue to emerge. Meanwhile, many new file systems are invented to support new hardware or features, often without undergoing comprehensive testing. To address these gaps, we develop a checking framework (Metis) that can thoroughly and efficiently test file systems and is easy to apply to a wide range of file systems. Metis helps developers and users identify file system bugs and offers directions for reproducing and fixing them.
Chameleon Is Coming to FAST 2024
Chameleon plans to co-host two BoF sessions to showcase FAST'24 artifacts created on Chameleon
- Feb. 1, 2024 by
- Marc Richardson
The REPETO project (an initiative funded by the NSF FAIROS RCN to build a network for practical reproducibility in experimental computer science) invites FAST’24 attendees to join our BoF sessions planned for February 27th and February 28th to learn about packaging storage research experiments on Chameleon. Pre-register with us for the BoF sessions by February 20, 2024 (link to interest form is in the blog!).
No comments