Storage Research Experiment Patterns on Chameleon Cloud and Trovi
- April 18, 2023
Authors: Ray A. O. Sinurat and Yuyang (Roy) Huang
What is the central challenge/hypothesis your experiment investigates?
In today's fast-paced world, technological advancement is vital, and reproducibility and extendability are crucial aspects of it. In fact, most top conferences now require researchers to create reproducible and repeatable experiments to ensure transparency and promote integrity. Unfortunately, this practice falls short, and sometimes, the experiment artifact itself is not runnable after publication, which makes it challenging to reproduce and extend other researchers' works. For instance, in the storage research field, we collected around 190 artifacts from top conferences and shockingly found that only 1% of them were reproducible and give us the same results. We observe that reproducing and extending experiments is a challenge due to the interdependence of code, analysis, and hardware. Fortunately, the Chameleon infrastructure offers a feasible solution by allowing experiments and their supported hardware to be colocated on the same platform, even making it possible to publish the artifacts publicly. Nevertheless, having this feature alone does not guarantee the extendability of the artifact. Therefore, having good methodologies and experiment patterns to support extendability and reproducibility is crucial.
How is your research addressing this challenge?
In our work, we seek to overcome these reproducibility and extensible experiments challenges by providing experiment patterns and guidelines that serve as the foundation for future research, including their integration with the Chameleon infrastructure. Our focus in this work is on storage research, but we believe that these patterns and guidelines can be applied in other fields of computer science, making reproducibility and extendability more achievable. So far, our works have been shown on several occasions, recently in Birds-of-a-Feather (BoF) session at FAST23 with the Chameleon team which can be seen in the photo below. Other than that, we also applied our methodologies in multiple community and educational events such as class environments and hackathons.

How do you structure your experiment on Chameleon?
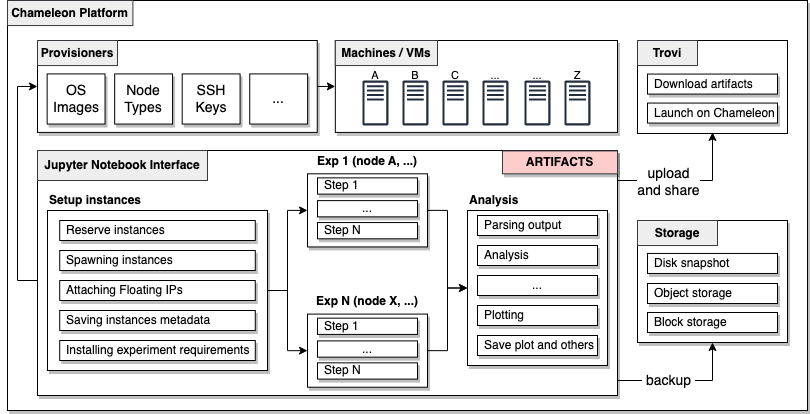
Our work is made possible by the powerful Chameleon infrastructure, as illustrated in the diagram above. We leverage the user-friendly Jupyter Notebook interface within Chameleon and divide our experiments into several steps contained in a single notebook file. When necessary, we break the experiment into multiple notebook files to facilitate extendability. We named this pattern the “breakable” pattern. After conducting the analysis and verifying reproducibility, we upload our experiments to Chameleon Trovi, making them available for others to reproduce and extend to their liking. To reserve and spawn instances, we utilized the Python CHI library, which is straightforward to use and can be extended using Python code. We also utilize a lot of CLI utilities to run experiment scripts inside the node. To get started with the storage research experiment, Chameleon Trovi provides numerous publicly available storage research experiments, making it an excellent resource for running storage experiments on the Chameleon platform.
What features of the testbed do you need in order to implement your experiment?
To conduct our experiments, we utilized bare-metal nodes that offer performance isolation, creating an ideal environment with minimal interference. Specifically, we spawned CPU nodes and storage nodes containing more than two disks in a single machine, which is particularly useful for storage researchers evaluating their work on multiple server-grade disk vendors for benchmarking purposes. Without access to Chameleon's infrastructure, running such experiments would be challenging, as it would be costly and difficult to provide multiple server-grade disk vendors ourselves. Fortunately, Chameleon offers an impressive range of storage resources, including the latest production disks, which can be found on Trovi. Although our work did not require the use of specific disk vendors, it is good to know that Chameleon provides such options for those who need them in the future.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
We recognize that building experiments with reproducibility and expandability in mind can be a daunting task for many researchers. That's why we've made several experiments available publicly to help researchers get started. We provide two simple benchmarks, the Simple FIO Benchmark on RAM disk and SSD, and Simple Filebench on ext4, that can be run without special nodes, making them accessible to anyone. We then improved these experiments by running them inside storage nodes that contain more than two disks, such as the FIO Benchmark on RAID-0, RAM disk, NVMe SSD, and Filebench on FSes, making them more suitable for storage researchers. For more advanced users, we offer the RDMA Benchmark, which utilizes InfiniBand interconnection widely used in high-performance computing (HPC) ecosystems, and the FlashNet experiment, our group research, which uses a neural network (NN) model to achieve per-I/O admission control in the AI era. These experiments are accessible on the Chameleon infrastructure and provide a great starting point for researchers looking to conduct storage experiments with reproducibility and extendability in mind. To find them easily, every experiment is tagged as “storage” to help people easily search the corresponding experiments using the query “tag:storage” inside the Chameleon Trovi search bar.
About the Authors
Ray A. O. Sinurat

Tell us a little bit about yourself
Ray A. O. Sinurat is a second-year CS Ph.D. student currently conducting computer system research in the UCARE system group at The University of Chicago. His research interests lie in improving the reliability, scalability, and performance of distributed and storage systems, where he strives to push the boundaries of what is currently possible. In addition, he is exploring the application of machine learning techniques to enhance cluster performance, a cutting-edge field with endless possibilities. He also firmly believes in the importance of reproducible and extensible research.
How do you stay motivated through a long research project?
Research projects, especially during Ph.D. years, are similar to a rollercoaster ride, with ups and downs that can be emotionally and mentally exhausting. To stay motivated, it's important to remember the reason we started this journey in the first place and reflect on the progress we've made. However, it's also important to take a step back and prioritize self-care. Remember, taking breaks and maintaining a work-life balance are crucial for our well-being and our ability to produce high-quality work. So, let's stay inspired, stay motivated, and take care of ourselves along the way.
Are there any researchers you admire? Can you describe why?
I'm incredibly grateful to so many people who have supported me throughout my research journey, but there are a few who stand out. First and foremost, I owe a debt of gratitude to my advisor, Prof. Haryadi S. Gunawi, who has not only mentored me but also taught me how to give back to the community. His unwavering trust in me has been a source of motivation during challenging times. Additionally, I have deep respect for the work of Edsger W. Dijkstra and other pioneering scientists who forged new paths in their fields, even when technology was not as advanced as it is today. Their ability to see beyond what was currently possible inspires me to push the boundaries of what we know and to continue to innovate.
Why did you choose this direction of research?
The computer system field, particularly distributed systems with machine learning integration, is a natural fit for me. I'm drawn to the creativity and outside-the-box thinking required to "hack" systems and find innovative solutions. What I love about this field is that there are often no perfect solutions, and we must constantly make trade-offs to achieve our goals. This challenge makes the work both interesting and fun and motivates me to keep pushing the boundaries of what is possible.
Yuyang (Roy) Huang

Tell us a little bit about yourself
Yuyang (Roy) Huang is a first-year Ph.D. student at the University of Chicago and working with the UCARE system group under the supervision of Prof. Haryadi Gunawi. His research interests include reliability, scalability, and performance analysis of distributed or storage systems. His current research project focuses on leveraging data science/machine learning techniques to analyze large-scale storage performance.
Why did you choose this direction of research?
As modern distributed systems in the industry become increasingly complex, I firmly believe that it is crucial to not only understand how these systems perform but also to have a methodology for analyzing their performance problems. And with a sophisticated methodology to analyze the systems we can better understand these problems in terms of why and how the problem happens, hence later when designing and implementing new systems, we can make more informed decisions to avoid such problems.
How do you stay motivated through a long research project?
Throughout a long research project, it is important to design a series of milestones to guide your progress. These milestones help you break down your work into manageable steps and provide opportunities to acknowledge and reward your achievements along the way. By setting achievable and reachable goals, you can maintain motivation throughout the project, rather than solely focusing on the final outcome which may be one or two years in the future.
Conducting Storage Research on Chameleon
- March 29, 2022 by
- Haryadi Gunawi
Chameleon has added lots of new and exciting storage capabilites in recent months - learn all about the resources available, how to conduct storage research on Chameleon, and examples of storage experiments being conducted by researchers at the University of Chicago, Carnegie Mellon University, Virginia Tech, and Rutgers University. There's also a fully packaged experiment and accompanying YouTube video that you can run on Trovi to practice with!
No comments