Conducting Storage Research on Chameleon
- March 29, 2022 by
- Haryadi Gunawi

Chameleon NVME nodes
Over the past decade, the storage market has grown enormously and with the explosion of big data, it continues to expand with efforts to optimize storing big data. For example, the solid-state drive (SSD) market is currently valued at $20--34 billion according to multiple sources and forecasted to reach $47--80.34 billion by 2025. Similarly, the non-volatile memory market is expected to reach $82 billion by 2022. As data is continuously collected and analyzed at large scales, storage research needs to continue to grow in all aspects, such as performance, reliability, manageability, security, among many others. To support this research, Chameleon took steps to expand and diversify the range of storage solutions it provides to users.
In the past few months, Chameleon has continued to expand its storage capabilities:
-
10 Dell R6525 nodes, each with 960GB Kioxia NVME SSD, 256GB RAM, 200G HDR Infiniband, 2x 25G Ethernet.
-
2 nodes each with 2x 7.68TB Intel Enterprise SSDs
-
2 nodes each with 2x 7.68TB Samsung Enterprise SSDs
-
2 nodes each with 4x 1.92TB Samsung Enterprise SSDs
-
2 nodes each with 2x 2TB Corsair Consumer SSDs
-
2 Dell R840 Quad-CPU nodes, with 112 Cores, 768Gb of RAM, and 3TB of Intel Optane NVDIMM, connected to the InfiniBand Fabric with 100GB/s HDR100
-
Including previous storage hierarchy nodes (4x Seagate 600GB HDDs,, 4x Intel 1.6TB SSDs, 2x Intel 2TB Optane NVME SSDs P3700) and traditional storage nodes (20 nodes with 1x Intel 400G SSD)
On top of all of these, Chameleon also provides many GPU nodes connected to the storage machines, fostering more hybrid storage/machine learning research. The last decade has witnessed significant growth in the development and application of artificial intelligence (AI) and machine learning (ML). Many industries, including storage, are either applying or planning to use AI/ML techniques to address their respective problem domains. In literature, we see an increase of research that leverages machine learning for solving system problems, such as management of networking, CPU/GPU, memory, energy, code analysis/compilation, and many forms of distributed systems. Likewise, with the significant increase of storage capabilities, Chameleon can cater to storage/machine learning research.
For academia, an important support Chameleon provides is for heterogeneous research. It can be challenging for academic researchers to acquire various storage devices from different vendors. Strong publications require strong evaluation of the storage stack across different types of devices. Typically academic researchers must reach out to some industry partners to have access to such devices. Purchasing enterprise SSDs is also becoming non-economical as many different models are required to evaluate the function of storage prototypes on different types of SSDs, but the devices are only heavily used near publication deadlines. For these reasons, the new Chameleon storage capabilities hopefully can meet the needs of the storage community in this space. Below are sharings from several storage researchers on how the community can use the nodes.
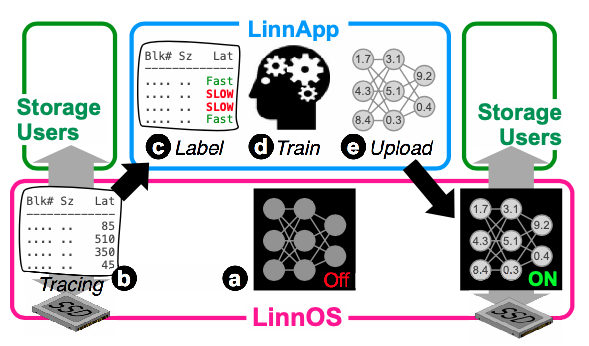
Figure 1: The LinnOS architecture with a light neural network that can learn heterogeneous consumer and datacenter SSDs.
Prof. Haryadi Gunawi’s team at the University of Chicago has been doing research on SSDs in the past few years. A prime example of his prior work that could have benefited from the Chameleon storage infrastructure is LinnOS, published at OSDI 2020, also packaged as a shareable experiment with Chameleon Trovi. This work addresses performance anomalies; such anomalies, even at the millisecond granularity, can cause monetary and productivity losses, and as a result, many varieties of storage products and services are advertised with percentile-based SLOs.A key to manage performance anomalies is latency prediction, which is becoming more challenging as devices are getting faster. In the LinnOS project, we examine whether we can build a machine learning model that can predict the speed (“fast” or “slow”) of every I/O that will be sent to an SSD device. For a strong evaluation of the model, his team needs to showcase that the model can work on various storage workloads and SSD models, both at consumer and enterprise levels. Fortunately his team managed to access three (expensive) enterprise-level SSDs. Various storage traces were run on various devices to collect different performance profiles with which the model can be trained. Chameleon’s support for heterogeneous SSDs will empower research like this one.
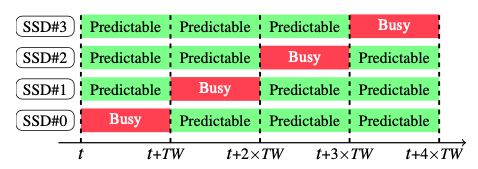
Figure 2: IODA’s time window (TW) contract for predictable latencies that was evaluated on Linux-managed flash array.
Dr. Huaicheng Li’s recent work requires an array of SSDs for tail-latency profiling and evaluating software policy designs to achieve predictable latencies (published at SOSP 2021, under the title of “IODA: A host/device co-design for strong predictability contract on model flash storage”). This is an important research problem to tackle as it can cause severe SLO violations on a large scale. Although IODA requires device-level access (hence the use of SSD emulators such as FEMU) to modify the host-SSD interface, the work requires baseline experiments running on bare flash arrays to show how Linux software RAID running on an array of SSDs suffers from performance limitations. Note SSDs are usually organized into RAID for reliability guarantees. For this, his team had to purchase a high-end machine with at least more than 4 PCIe slots to attach 4 SSDs and other peripherals and set up a flash array using Linux software RAID. Today, Chameleon also supports flash array research with 2 nodes running 4 SSDs (including many other machines running multiple disks). Users can install their own Linux and modify the Linux Software RAID layer. Other papers that can use the Chameleon storage infrastructure include: Harmonia [MSST 11], Geoko [FAST 13], FlashOnRails [ATC 14], Purity [SIGMOD 15], SWAN [ATC 19], RAIL [TOS 21].
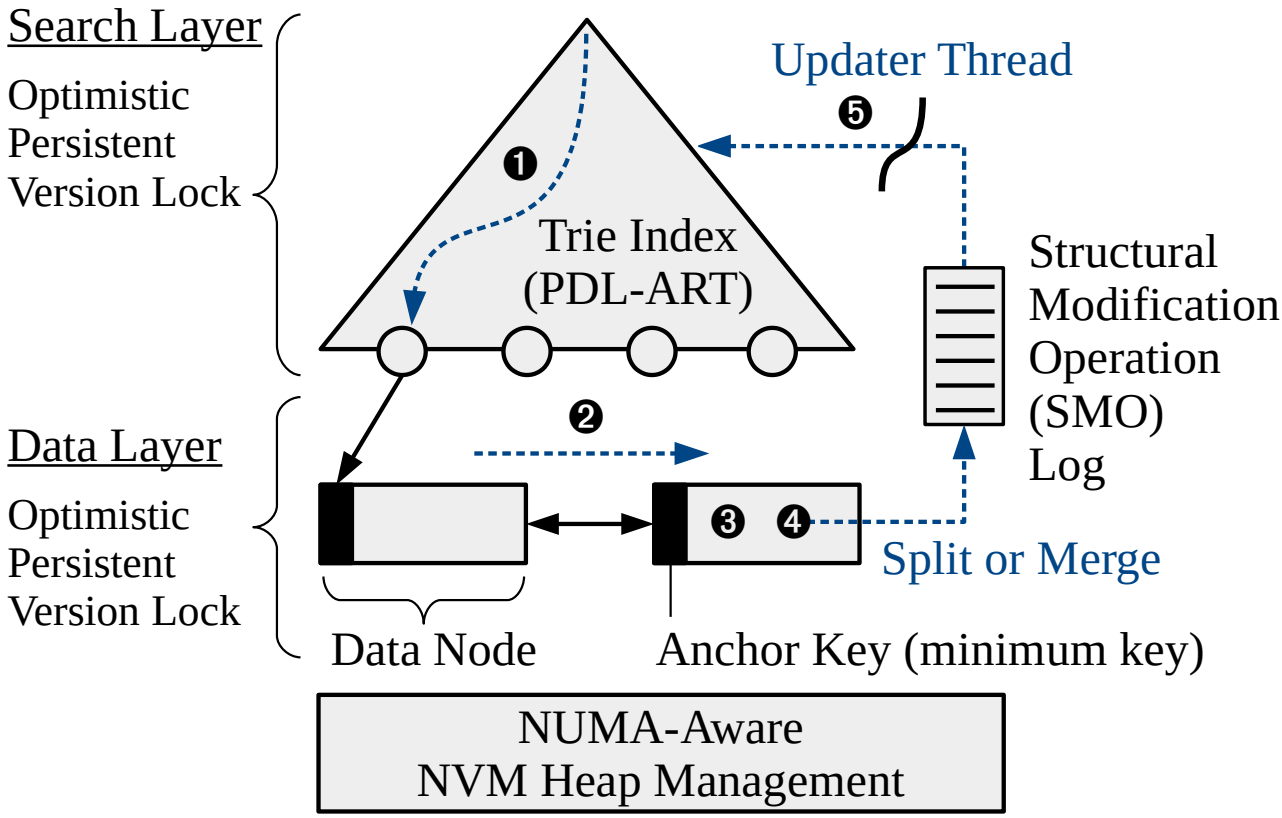
Figure 3: PACTree achieves high performance and scalability on Intel Optane PM by reducing PM bandwidth consumption and asynchronous concurrency control.
Prof. Changwoo Min’s team at Virginia Tech has been working on storage systems optimized for byte-addressable persistent memory (PM). One example is PACTree, a highly scalable persistent key-value store optimized for Intel Optane PM, published in SOSP 2021. His team first conducted a performance characterization study of Optane PM to understand the performance and scalability of the real PM hardware. The key findings are (1) PM bandwidth would be the first bottleneck in PM-optimized storage stacks and (2) slow PM write latency could be a scalability bottleneck. Based on the findings, his team designed the new key-value store, PACTree, which reduces PM bandwidth consumption and avoids the slow PM latency being a scalability bottleneck. His team needs a multi-core machine (with a high core count) with Optane PM to demonstrate the performance and scalability of PACTree. Through collaboration, his team could access such a high-core count PM machine. Today, Chameleon supports PM servers equipped with Optane PM (3TB) and 4-socket Xeon processors (112 cores). Not only PACTree [SOSP21] but also other works, such as TIPS [ATC 21] and TimeStone [ASPLOS 20], can be run on Chameleon infrastructure.
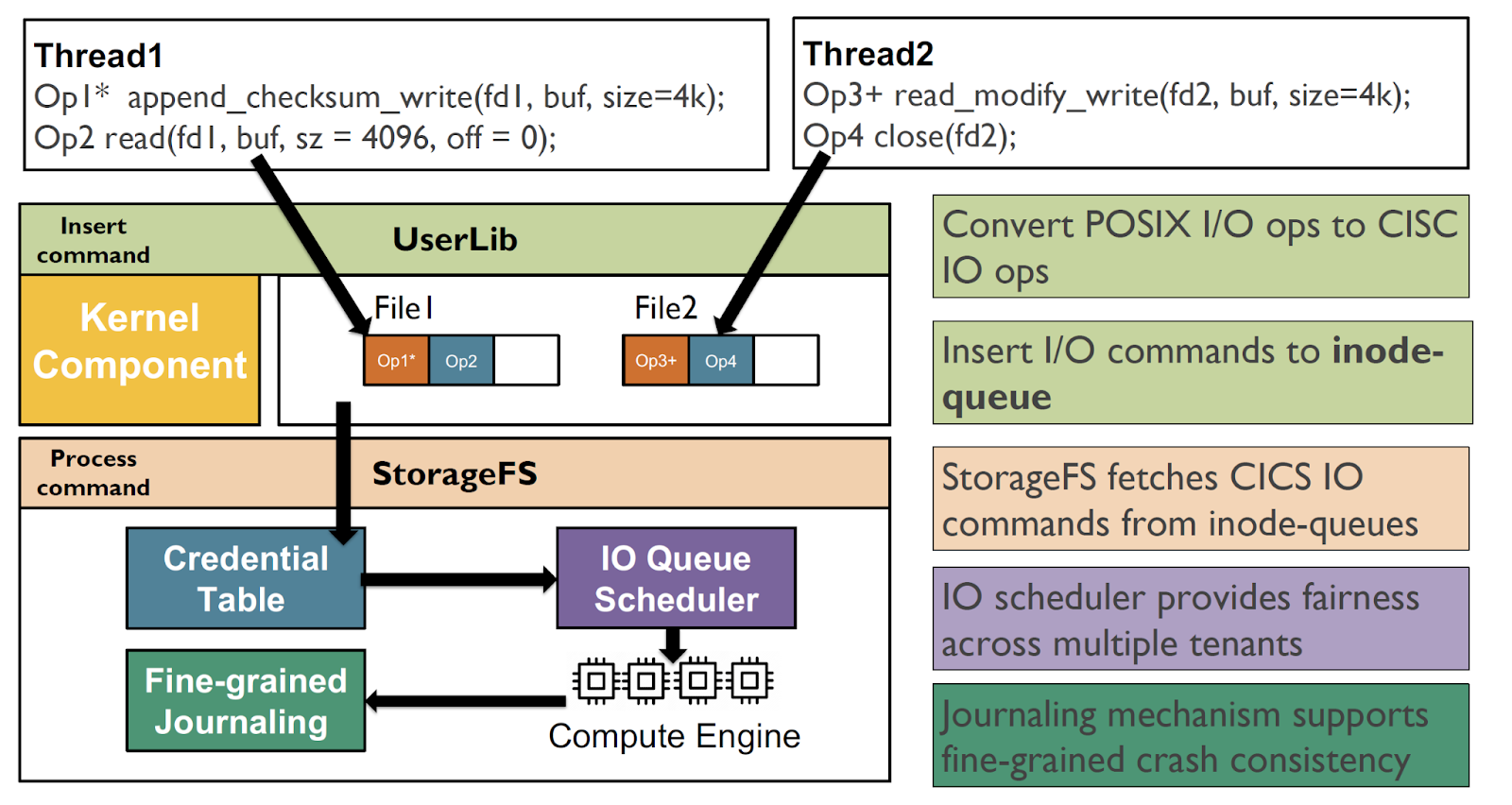
Figure 4: Cross-layered file system design split across the userspace, the storage, and the OS. Applications and runtimes use the cross-layered design to offload traditional I/O operations and data processing operations fused as CISC-styled operations to exploit the capabilities of in-storage computation.
Prof. Sudarsun Kannan's team at Rutgers has been working on understanding the benefits and implications of near-storage computing and memory heterogeneity. For example, his group's recent near-storage computing and heterogeneity research appeared in venues like OSDI 2020 (CrossFS), FAST 2022 (FusionFS), and ASPLOS 2021 (KLOCs). CrossFS identified the benefits of disaggregating the file systems across the userspace, the storage, and the OS for higher I/O performance and fine-grained concurrency. FusionFS extended CrossFS to design CISC-styled (Complex Instruction Set Computer) I/O operations to organically offload data for near-storage processing and reduce I/O costs like data movement, system calls, and PCIe communication. In contrast, KLOCs explored the benefits of memory heterogeneity using Optane memory. Fortunately, his team got access to Optane PMs through collaboration with other groups but had to emulate near-storage computing devices. The presence of Optane PMs and near-storage computing devices (for example, SmartSSD) in Chameleon would provide an opportunity for his group and other researchers to conduct more detailed studies using real devices and explore new dimensions for utilizing near-storage computing and storage heterogeneity.
To help the storage community test out the new storage nodes, Ray Andrew, a UChicago PhD student has created a simple experiment package (using Chameleon's Trovi feature) which you can reproduce and run here: https://www.chameleoncloud.org/experiment/share/81?s=a8199ef35ffa48d5828d4b9a45a6385e
This experiment runs the FIO benchmarks on the NVMe devices and generates a simple read/write throughput graph. Ray has also provided a YouTube video on how to use this package: https://www.youtube.com/watch?v=grUOrKkiYuQ
No comments