Tigon: A Distributed Database for a CXL Pod
Leveraging Shared CXL Memory to Break Through Traditional Network Bottlenecks
- Aug. 27, 2025 by
- Yibo Huang
Tigon: A Distributed Database for a CXL Pod
The Bottleneck in Today's Distributed Databases
Imagine you are a manager leading a project that requires work from several departments in your company, each in a different city. To get the project done, you divide it into smaller tasks based on each department’s responsibility and email them their assignments. Then, you wait. Each department works on its task and emails the results back to you. Only after you have received and collected all the replies can you finalize the project.
This organizational structure is very similar to how today’s distributed databases work: they divide data into multiple partitions and store them on different hosts. And the multi-step process for completing the project mirrors how these databases execute transactions that need to access data on multiple hosts. A coordinator sends network requests to the relevant hosts, waits for them to complete their work, and then proceeds. This multi-step communication process, inherent to the partitioned design, introduces significant performance overhead.
Tigon: Replacing Network Communication with Shared Memory
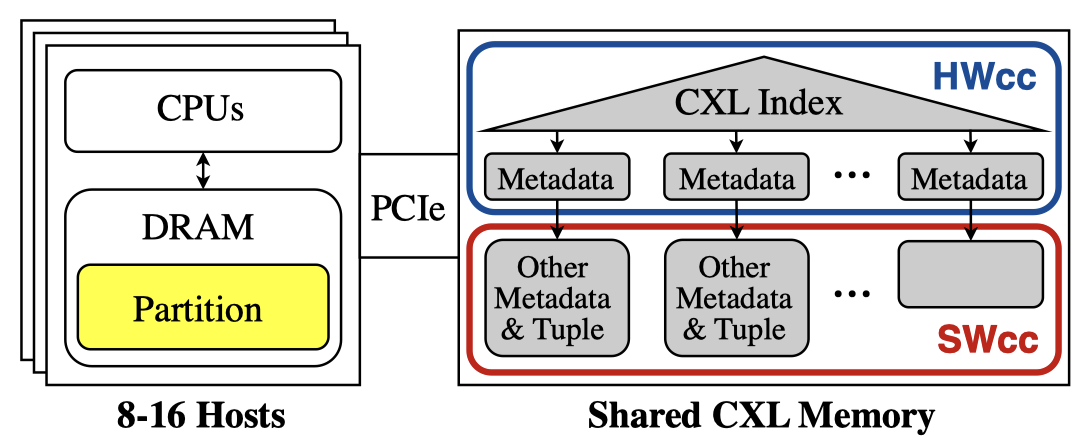
Our project, Tigon, tackles this overhead by leveraging a new technology called Compute Express Link (CXL). CXL allows multiple hosts to connect to a shared memory device via PCIe, creating what we call a "CXL pod". This architecture makes it possible to store all data in shared memory, enabling hosts to access any piece of data and synchronize with each other by performing atomic operations directly on that memory. This bypasses the slow and complex process of sending network messages entirely.
However, CXL memory must be used with care. While much faster than a network, it's slower than a host’s own local memory (DRAM) and has limited hardware support for inter-host cache coherence. To maximize CXL's benefits while avoiding its weaknesses, Tigon uses a hybrid approach. It starts by partitioning data across each host's local, high-speed DRAM. Then, Tigon intelligently moves only the small subset of data that is being actively accessed by multiple hosts into the shared CXL memory. This way, Tigon gets the massive speed benefit of direct memory access for shared data without being slowed down by CXL's limitations for local data.
The results are significant: Tigon achieves up to 2.5x higher throughput than traditional shared-nothing databases and 18.5x higher throughput than an RDMA-based distributed database.
Developing and Evaluating Tigon on Chameleon
Our research on Tigon was brought to life on Chameleon. CXL is a cutting-edge technology, and physical hardware for a multi-host CXL pod was not commercially available during our work. We needed a way to build and test for this future environment today. Chameleon’s powerful bare-metal servers gave us the low-level control needed to emulate this next-generation hardware. Using a compute_icelake_r650 node at TACC, we were able to emulate CXL memory using remote NUMA memory. On a single physical node, we configured eight Virtual Machines (VMs) to act as the "hosts" in our CXL pod and configured them to share the emulated CXL memory device. This allowed us to precisely emulate the target environment for Tigon and run the extensive performance tests needed to validate our design.
Explore Our Work
About the Author

I am Yibo Huang, a Ph.D. student at The University of Texas at Austin, advised by Prof. Emmett Witchel and Prof. Dixin Tang. My research focuses on efficient data systems on shared CXL memory.
For more details, please visit my homepage: https://yibo-huang.github.io/
Most powerful piece of advice for students beginning research or finding a new research project?
Be open-minded. Be ready to have your best ideas be wrong.
Why This Research?
For decades, the architecture of distributed databases has been dictated by the limitations of the network. We've developed incredibly complex software to work around this fundamental bottleneck. When I started learning about CXL, I saw an opportunity to challenge that core assumption. What if the network was no longer the only way for computers to communicate? Exploring that question led directly to the ideas behind Tigon. It's exciting to work in an area where hardware advancements are opening the door to completely new software designs.
Minimizing Out-of-Memory Failures in Genomics Workflow Execution
Reducing Workflow Failures with Chameleon’s Scalable Research Platform
- Dec. 30, 2024 by
- Aaditya Mankar
Processing large-scale genomics data efficiently is a monumental task, often hindered by high costs and resource allocation challenges. This blog dives into an innovative system designed to optimize genomics workflows by minimizing out-of-memory failures—a critical bottleneck in such operations. Through a combination of scalable benchmarking tools and a failure-aware scheduler, researchers are unlocking new possibilities for resource efficiency and reliability. Leveraging insights from Chameleon, this solution paves the way for groundbreaking advancements in genomic data processing.
Rethinking Memory Management for Multi-Tiered Systems
Exploring Efficient Page Profiling and Migration in Large Heterogeneous Memory
- July 22, 2024 by
- Dong Li
Explore the cutting-edge research of Professor Dong Li from UC Merced as he tackles the challenges of managing multi-tiered memory systems. Learn how his innovative MTM (Multi-Tiered Memory Management) system optimizes page profiling and migration in large heterogeneous memory environments. Discover how Chameleon's unique hardware capabilities enabled this groundbreaking experiment, and gain insights into the future of high-performance computing memory management. This blog offers a glimpse into the complex world of computer memory hierarchies and how researchers are working to make them more efficient and accessible.
Exploring Process-in-memory Architecture for High-performance Graph Pattern Mining
- June 20, 2022 by
- Rujia Wang
Graph Pattern Mining (GPMI) applications are considered a new class of data-intensive applications -- they generate massive irregular computation workloads and pose memory access challenges, which degrade the performance and scalability significantly. Researchers at the Illinois Institute of Technology approach the problem by using the emerging process-in-memory architecture.
No comments