Connecting Continents: Dynamic Deployment of Transatlantic Computational Testbeds via the Infrastructure Manager
Breaking down the barriers between cloud computing 'silos' to create unified, large-scale scientific environments that span across Europe and the United States.
- July 28, 2025 by
- Germán Moltó Martínez
We talked with Germán Moltó, Full Professor at Universitat Politècnica de València, about his work on interconnecting cloud infrastructures to support complex scientific research. His team’s recent experiment showcases how to bridge cloud federations in Europe and the United States, creating powerful, transatlantic computational testbeds.

Research Overview
Cloud-based infrastructures provide the computational substrate to efficiently execute compute-intensive scientific experiments on customized virtualized resources which include disparate software configuration and/or hardware resources (e.g. GPUs). However, many cloud infrastructures operate as independent silos and, therefore, users find it difficult to collaboratively aggregate resources from different clouds in a unified customized testbed to untap access to large-scale computing capacity. This work focuses on the automated deployment of customized computational testbeds that span across distributed cloud infrastructures. This required introducing support in a cloud orchestrator that interacts with the underlying cloud infrastructures without requiring modifications in each particular cloud site, thus facilitating user adoption.
Experiment Implementation on Chameleon
Our Approach
This research involved introducing Chameleon cloud support in the Infrastructure Manager (IM), an open-source cloud orchestrator that deploys complex virtualized application architectures on multiple cloud back-ends (Amazon Web Services, Microsoft Azure, OpenStack, etc.). The IM is being used in production as the cloud orchestrator in the EGI Federated cloud. EGI is the largest federation of research data centres contributing with storage and compute facilities, while EGI Federated cloud is a large federation of OpenStack-based cloud sites contributed by more than 20 research centres mainly across Europe. As shown in the figure below, the IM provides a curated catalog of popular applications commonly used in scientific research and data-intensive processing (e.g. Galaxy, Dask, AirFlow, JupyterHub), thus providing users with the ability to deploy in minutes their preferred computational environment.


UPV (Universitat Politècnica de València), in Spain, provides a publicly available instance of the Infrastructure Manager, offered as part of the EGI service catalogue, openly accessible to anyone, to deploy on any of the supported cloud infrastructures on behalf of the user. Our approach involves introducing Chameleon Cloud as an additional cloud back-end supported by the IM and deploy transatlantic testbeds to execute use cases coming from European projects to unveil the benefits of aggregating computing resources from disparate cloud sites (e.g. EGI Federated cloud and Chameleon Cloud).
Building the Experiment
Integrating Chameleon Cloud to be used as a Cloud back-end for the Infrastructure Manager required understanding the platform via the documentation, accessing the capabilities and hardware availability via the hardware catalog and getting access to OpenStack’s Application Credentials which are securely stored in a Hashicorp’s Vault instance. Chameleon’s Helpdesk played a pivotal role in interacting with the team to facilitate access to relevant information.
Using the IM we deployed examples of transatlantic Virtualized Computing Infrastructures (VCIs) across the OpenStack-based Clouds provided by both Chameleon Cloud and EGI Cloud Compute service to facilitate distributed computation. In particular, we deployed two OSCAR clusters (an open-source event-driven serverless platform based on Kubernetes) via the IM, one in US (Texas Advanced Computing Center) and another in the EU (Portugal).
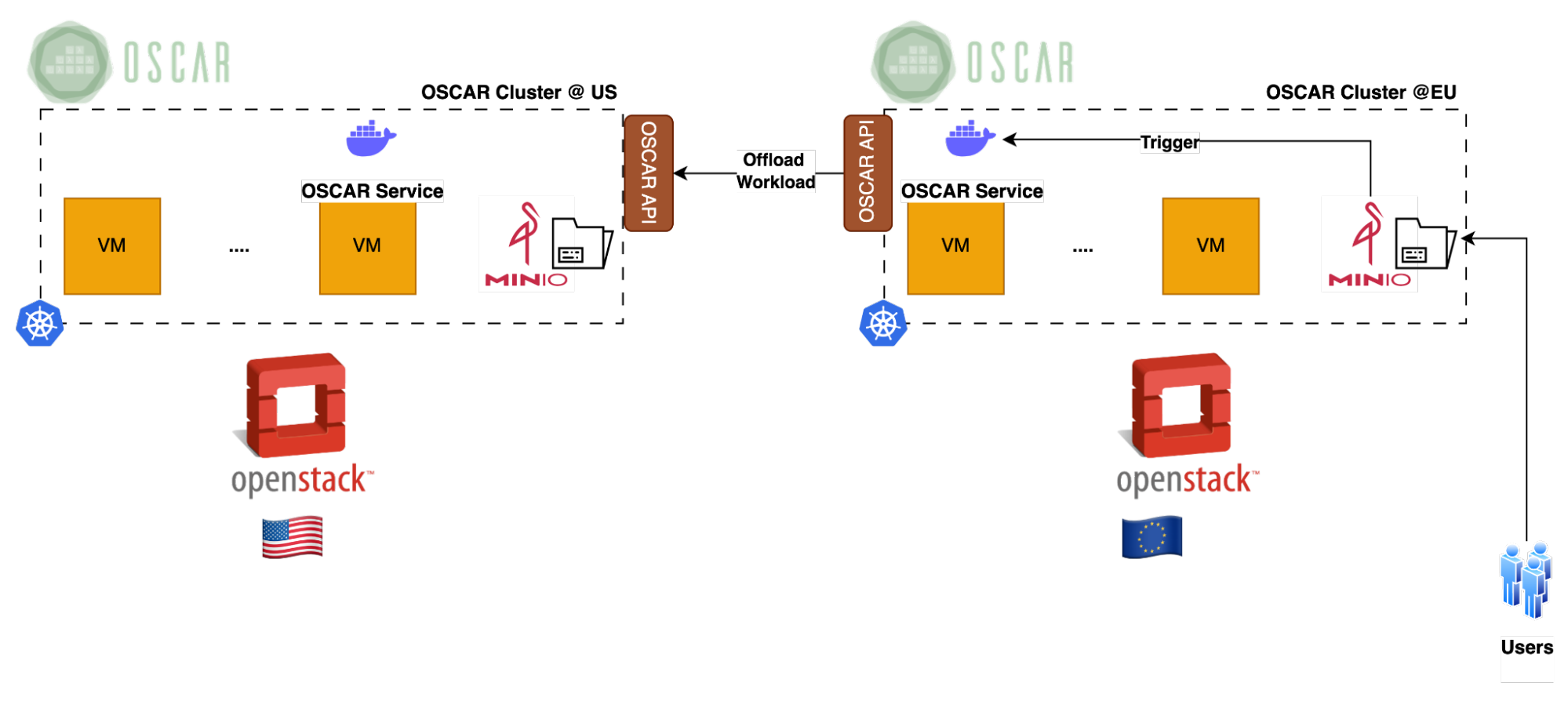
We supported a use case on distributed AI-based fish detection coming from the iMagine EU (European Union) project across the resources of this transatlantic testbed. For the deployment of services in each cluster, an OSCAR services replicated architecture has been used. This allows that invocations made to a service deployed in OSCAR Cluster @EU that have not been executed for a certain configurable amount of time (due to the lack of computing resources) are redirected to the corresponding services in the OSCAR Cluster @US. The invocations of the services executed in the OSCAR Cluster @US not only return the results in their local bucket but also return them to the bucket of the corresponding service in the OSCAR Cluster @EU.
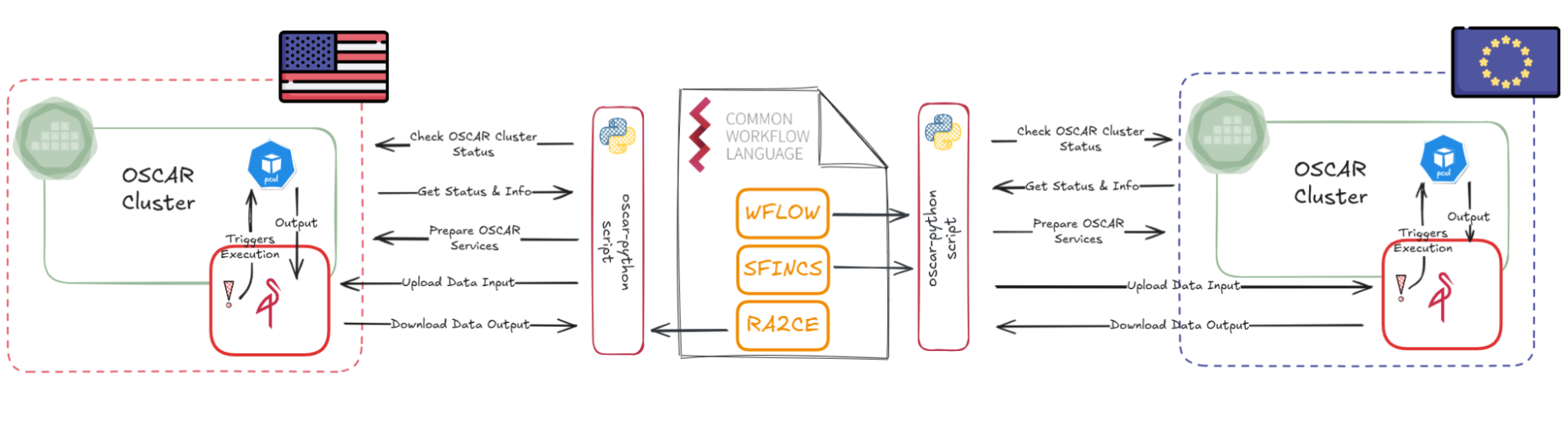
We also supported another use case on Flood Assessment coming from the interTwin EU project where a CWL (Common Workflow Language) configuration is created from a Jupyter Notebook to include the configuration required for the Digital Twin and is later executed so that some computationally-intensive steps of the workflow are offloaded to a remote OSCAR cluster running on Chameleon Cloud. A Python script invoked by the CWL workflow, which performs all necessary operations within the OSCAR environment, ensuring that the model executes correctly, processes the required tasks, and retrieves and downloads the output seamlessly.
Essential Testbed Features
This experiment was done using virtualized infrastructure provided by KVM@TACC, but a similar approach can be done in bare-metal resources since support for the Blazar reservation was introduced in the plugin developed to interact with Chameleon Cloud, and contributed upstream to the Apache Libcloud’s library.
Experiment Artifacts
For those interested in exploring this work further, the following resources are available:
- Supporting slides including video demos
- GitHub repository for the Fish Detector replicas deployed across OSCAR clusters
- Trovi artifact “Deploy Applications on Chameleon via the Infrastructure Manager (IM)”
- Related Press Notes:
User Interview
About the Researcher
Germán Moltó is Full Professor at Universitat Politècnica de València, specializing in distributed computing, cloud computing, and serverless computing. With a strong background in middleware technologies, orchestration, and cloud automation, our group’s research has contributed to the advancement of scalable deployment and execution of applications on distributed computing infrastructures. He has contributed to numerous European projects in the area of the European Open Science Cloud (EOSC) such as EOSC-Synergy, EOSC-Hub and EOSC-Beyond. His team is responsible for open-source developments in the area of cloud orchestration and execution of applications along the computing continuum.
Motivation and Advice
Most powerful piece of advice for students beginning research or finding a new research project?
It’s not about being smart, it’s about consistency and discipline. Hard work always pays off.
How do you stay motivated through a long research project?
I like when research projects involve interconnecting multiple software systems and services to facilitate a specific area of the research lifecycle (e.g. access to computing capacity, deploying a virtual research environment, etc.). Providing gateways for scientific end users to take advantage of distributed computing infrastructures is a rewarding experience and being able to contribute with our research group’s expertise provides a significant energy boost.
Part of these results were funded via a research stay by the DISCOVER-US project, financed by the European Union’s Horizon Europe research and innovation funding programme under grant agreement number 101135064. Results presented in this presentation were obtained using the Chameleon testbed supported by the National Science Foundation. We acknowledge Grant PID2020-113126RB-I00 funded by MICIU/AEI/10.13039/501100011033. Part of this work was supported by the project AI4EOSC ‘‘Artificial Intelligence for the European Open Science Cloud’’ that has received funding from the European Union’s Horizon Europe Research and Innovation Programme under Grant 101058593. Also, the project iMagine ‘‘AI-based image data analysis tools for aquatic research’’ that has received funding from the European Union’s Horizon Europe Research and Innovation Programme under Grant 101058625. These results were achieved thanks to the support effort from Miguel Caballer, Estíbaliz Parcero and Vicente Rodríguez.
Infrastructure without Scaling Limits
Exploring Statistical Multiplexed Computing for Unlimited Infrastructure Scaling
- June 25, 2025 by
- Justin Shi
IT infrastructure forms the backbone of modern society, but traditional scaling approaches face critical limitations that expose services to security and reliability shortcomings. This research investigates Statistical Multiplexed Computing (SMC) principles to build infrastructures without scaling limits, similar to how TCP/IP protocols enabled indefinite network scaling.
Connecting SLICES-RI and Chameleon
An Approach towards Portable, Reproducible Experiments
- April 22, 2024
One Fish, Two Fish: Choosing Optimal Edge Topologies for Real-Time Autonomous Fish Surveys
- April 18, 2022 by
- Jonathan Tsen
Learn how researchers are pairing autonomous vehicles with Chameleon to bridge edge to cloud computation to conduct marine surveys. Featuring work presented at the 2021 Supercomputing conference, with a notebook available on Trovi that you can reproduce yourself, and a YouTube video to accompany it!
No comments