EditLord: Learning Code Transformation Rules for Code Editing
Making code edits more effective, robust, and transparent through explicit transformation rules
- March 24, 2025 by
- Weichen Li
Code editing is a fundamental task in software development, and its effectiveness can significantly impact the quality and reliability of software products. Traditionally, code editing has been treated as an implicit, end-to-end task, overlooking the fact that it consists of discrete, clear steps. This research introduces EditLord, a novel approach that makes these transformation steps explicit and leverages language models to learn concise editing rules from examples.
Research Overview
Our experiment addresses the challenge of making code editing more effective, robust and interpretable. Code editing is a foundational task in software development, where its effectiveness depends on whether it introduces desired code property changes without breaking the original functionality. Traditionally, code editing is treated as one implicit, end-to-end task, omitting the fact that code editing procedures actually consist of clear, discrete steps. Our hypothesis is that by making these transformation steps explicit and leveraging a language model to learn concise editing rules from examples, we can significantly enhance the editing process.
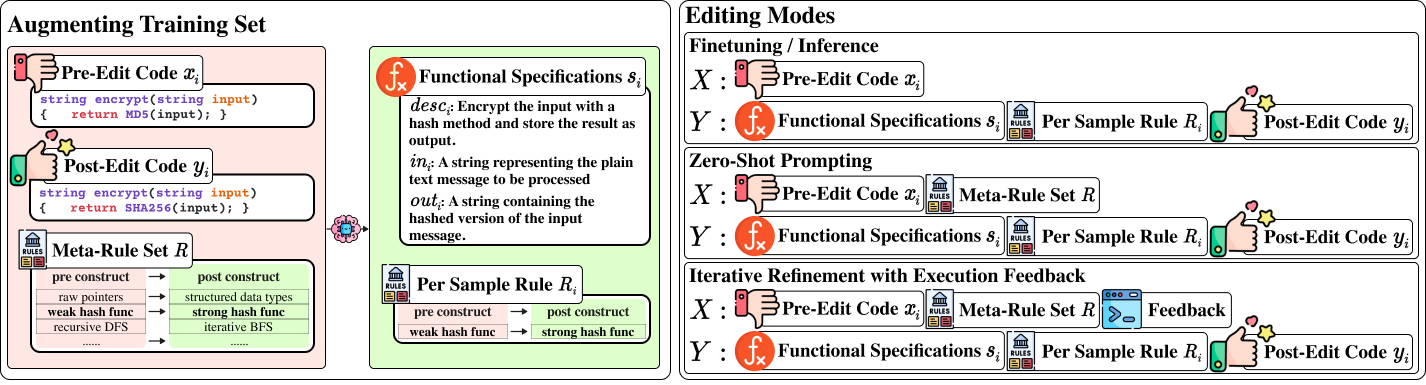
Consider the readability improvement task: instead of rewriting the code all at once, you make specific, deliberate changes to individual statements. Similarly, EditLord extracts meta-rule sets that guide the editing process, ensuring that each step is accurate and robust. Day-to-day, this research can lead to more reliable software updates, quicker bug fixes, and improved security in critical applications. EditLord boosts editing performance by around 22.7%, enhances robustness by 58.1%, and achieves 20.2% higher functional correctness, marking a substantial leap in the quality and efficiency of software development.
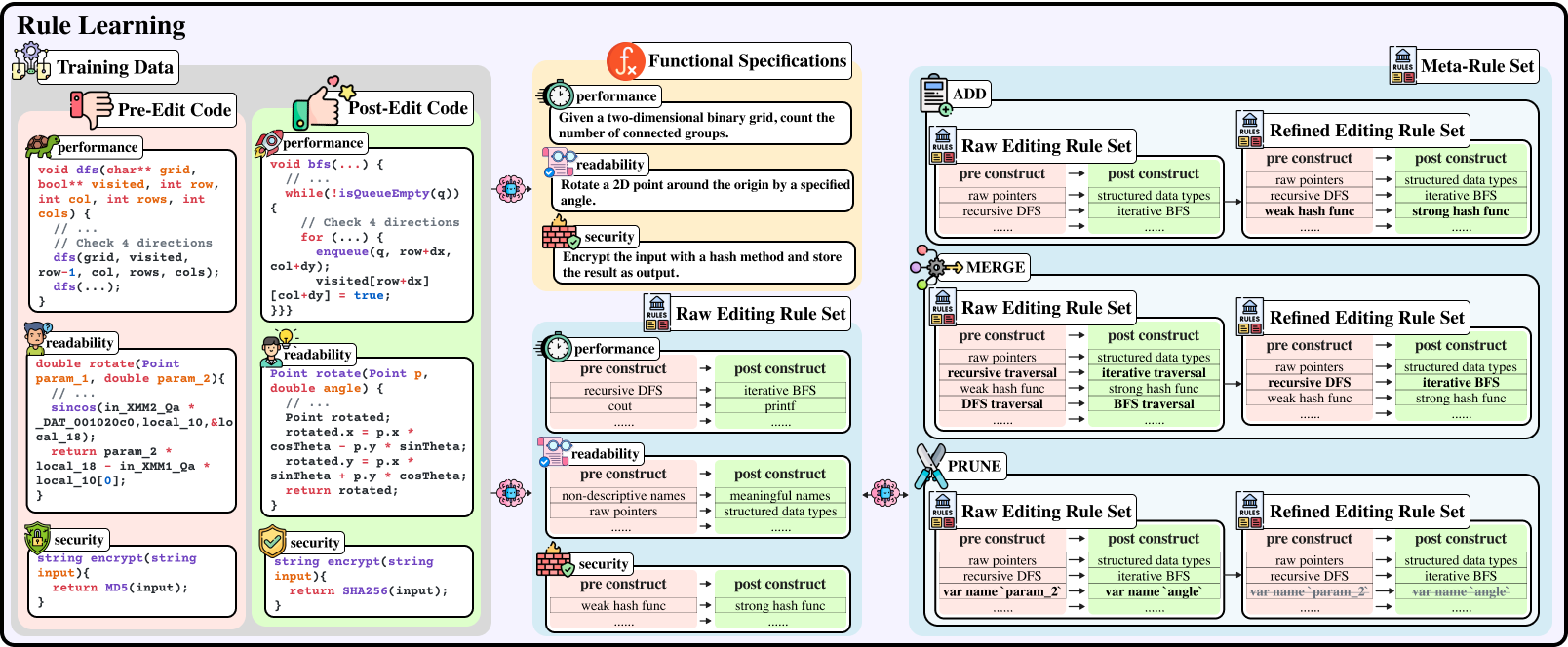
We break code editing into clear, step-by-step transformations rather than treating it as a mysterious black box. Instead of expecting an AI to generate a completely new version of code in one go, our approach teaches the system to learn explicit transformation rules from examples of code before and after edits. Think of it as instructing a handyman to follow a detailed checklist—each step is transparent and easy to verify.
Our method has three main parts. First, we use a language model to analyze pairs of original and edited code to discover specific transformation rules. These rules are then refined through an iterative process that merges similar changes and prunes overly specific ones, forming a concise "meta-rule set." Second, we extract functional specifications from the code, which are simple descriptions of what the code is supposed to do, to ensure that the edits preserve its intended behaviour. Finally, we combine these learned rules and functional summaries to guide the editing process, whether by fine-tuning the model or directly prompting.
In our experiments, EditLord achieved an average improvement in editing performance of 22.7%, enhanced robustness by 58.1%, and improved functional correctness by 20.2% compared to existing methods.
With EditLord, developers can be more aware of what the language model is doing during code editing and intervene with it by introducing custom editing rules for intended changes.
Experiment Implementation on Chameleon
In our research, we set up and ran our performance evaluations on Chameleon. We start by selecting the appropriate hardware through the hardware catalog and verifying resource availability with the host availability browser. This ensures that our experimental environment meets our specific requirements.
Then, we configure the environment via command-line tools. While the GUI and Jupyter interfaces are available, we find that the command line provides a faster and more reproducible workflow for our performance evaluations.
For those setting up similar experiments: start with the hardware catalog and host availability browser early on to match your experimental needs with available resources, and rely on the documentation to navigate common configuration challenges.
We rely on several unique Chameleon features to ensure a controlled, reproducible environment and eliminate bare-metal issues. Specifically, we use bare-metal reconfiguration and custom kernel boot to establish a clean system state and access the serial console for low-level debugging. These features are essential for maintaining consistent test conditions and isolating performance metrics. Without these features, experiments would be more error-prone and less reproducible, potentially forcing us to adjust our hypothesis or design to account for additional variability.
Experiment Artifacts
The specific code repo we run on Chameleon: https://github.com/kleinercubs/pie
User Interview

Tell us a little bit about yourself
I'm currently a first-year PhD student at the University of Chicago, where I focus on research in programming languages, security, software engineering, and machine learning. I hope to make impactful contributions in my fields, whether in academia or industry. Ultimately, I aim to develop innovative solutions that address key challenges in programming and security.
Most powerful piece of advice for students beginning research or finding a new research project?
Embrace curiosity and be open to uncertainty. Rather than waiting for a perfectly formed research question, we should let our interests guide us. Explore broadly, ask thoughtful questions, and push the boundaries of your research environment. Don't be discouraged by poor experimental results—these setbacks can reveal powerful insights. Engage with mentors and peers, read widely, and don't be afraid to take risks. Often, the most impactful discoveries arise from the questions that truly ignite our curiosity.
How do you stay motivated through a long research project?
I stay motivated throughout long research projects by focusing on the incremental progress and the larger impact my work can have. Even when the pace feels slow, I remind myself that each small breakthrough contributes to the overall discovery process.
What has been a tough moment for you either in your life or throughout your career? How did you deal with it? How did it influence your future work direction?
During research, encountering setbacks, e.g., a promising experiment not yielding expected results, can be tough. Instead of viewing it as a setback, I took time to analyze what went wrong and discussed the issues with my peers and mentors. This experience not only deepened my understanding but also shifted my research direction to focus on more innovative solutions, ultimately leading to new insights.
Thank you for sharing your work with the Chameleon Community!
If At First You Don't Succeed, Try, Try, Again...? Insights and LLM-Informed Tooling for Detecting Retry Bugs in Software Systems
Using Chameleon to Hunt Down Elusive Retry Bugs in Software Systems
- Oct. 21, 2024 by
- Bogdan-Alexandru Stoica
Discover how Bogdan Stoica and researchers at the University of Chicago developed Wasabi, an innovative tool that combines fault injection, static analysis, and large language models to detect and analyze retry-related bugs in complex software systems. Learn how Chameleon's bare-metal capabilities enabled precise testing environments for this fascinating research published at SOSP'24.
How to Train a GPT From Scratch
An experiment reproducing NanoGPT and lessons learned
- Jan. 24, 2024 by
- Akash Kundu
No comments