Empowering the Edge: Breaking Heterogeneity Barriers in Cloud-based ML Training
Optimizing Federated Learning for Heterogeneous Edge Devices
- Nov. 25, 2024 by
- Redwan Ibne Seraj Khan
Machine learning is now everywhere, with applications in medical science, finance, autonomous cars, smart cities etc. This has led to the rise of Federated Learning (FL), enabling distributed, collaborative training using end-user data. FL, with a market value of over hundred million dollars and a projected annual growth rate of 10.7%, holds great potential but comes with heterogeneity challenges in client devices' computing power, network, availability, data sample size and count, and memory, making FL more challenging than traditional distributed Machine Learning (ML).
While current literature addresses FL performance by tackling computing and communication heterogeneity, strategies for data sample and memory heterogeneity remain largely unexplored. High-end computing capabilities in modern devices reduce computing time, making data fetching from storage, i.e., I/O the primary bottleneck. I/O bottleneck could be resolved using caching but trying to adopt caching strategies in FL requires rethinking how to orchestrate three connected components--(1) client scheduling, (2) client data sampling, and (3) client data sample caching--in such a way that can improve the training time and accuracy convergence of FL workloads.
Research Overview
Motivated by the urge to address the heterogeneity challenges in FL, I designed FedCaSe, a novel framework for Federated Learning that unifies client scheduling, data sampling, and caching to optimize performance for massively heterogeneous edge devices in the cloud. FedCaSe introduces a key innovation: leveraging the experience of both data samples and clients---their relative impact on overall performance metrics---to guide caching and scheduling decisions. By exploiting this experience, FedCaSe dynamically optimizes the placement of high-impact data within the limited memory of edge devices and orchestrates the selection of clients to maximize training efficiency.
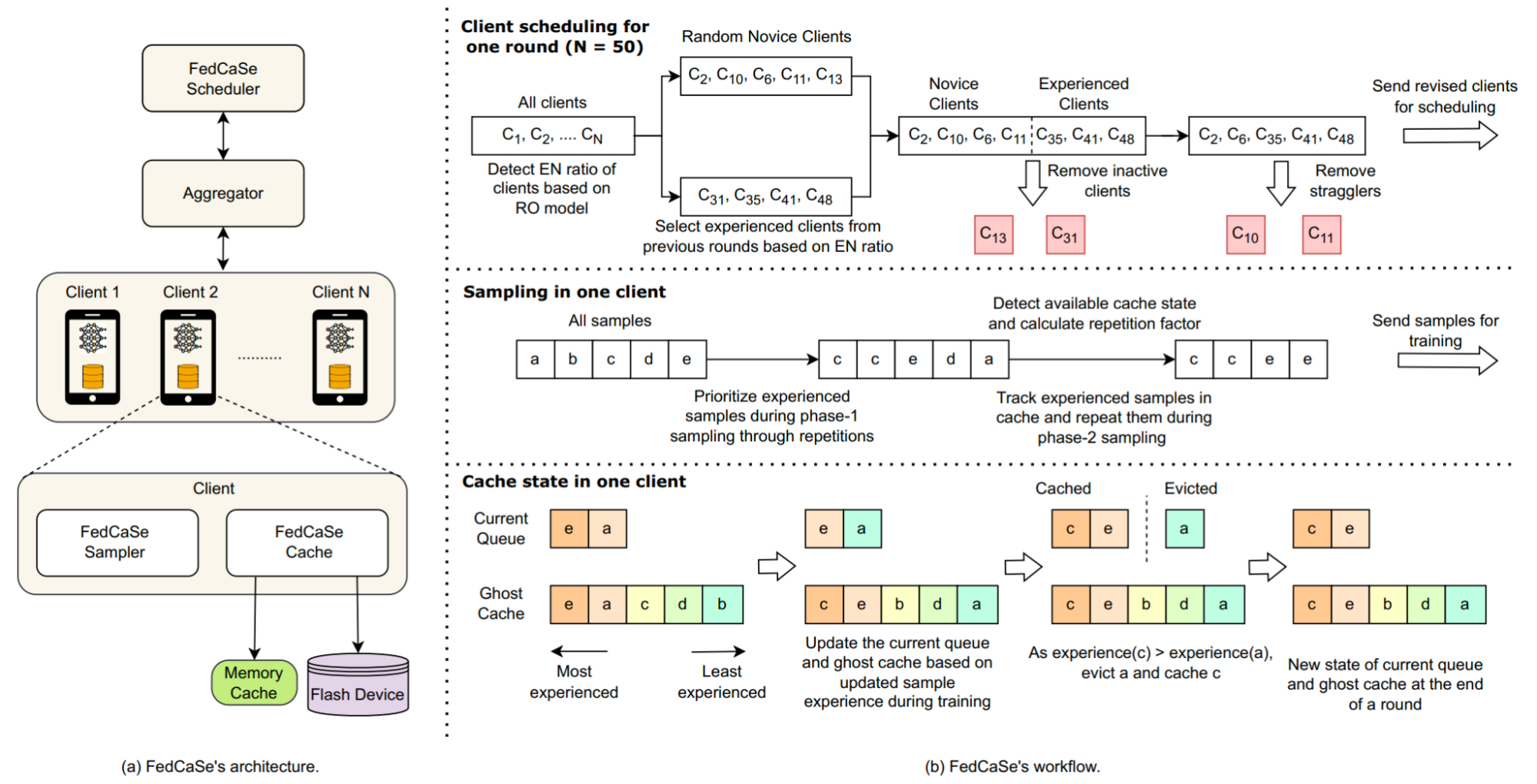
My experiments with representative workloads and policies show that compared to the state-of-the-art, FedCaSe improves the experienced client participation up to 29.1x, improves the global read hit ratio (RHR) across all clients by up to 81.7x (locally up to 318.58x), and thus ensures accuracy improvement rate up to 2.06x faster based on wall clock time, up to 1.4x faster based on number of rounds while keeping the round duration up to 2.4x less. These results demonstrate FedCaSe's ability to overcome the I/O bottleneck and unlock the full potential of FL systems in heterogeneous devices in the cloud. By addressing a critical pain point in FL deployments, FedCaSe paves the way for broader adoption of edge-based AI, enabling a wide range of applications, from healthcare diagnostics to personalized learning systems.
Experimental Implementation
Chameleon Cloud provided an ideal platform for running my experiments, offering state-of-the-art GPU and storage solutions tailored to my research needs. Specifically, I used P100 GPUs provided by CHI@TACC, which were critical for my deep learning workloads.
Reserving bare-metal nodes through Chameleon's intuitive GUI greatly simplified the setup process. The hardware catalog allowed me to quickly identify nodes with the configurations I needed, and the host availability browser enabled me to plan my experiments efficiently. When my experiments ran for days, extending leases via the GUI was seamless. On occasions when my reserved nodes were leased to others, the Chameleon staff was incredibly supportive in resolving conflicts, ensuring my experiments continued without disruption by reallocating equivalent resources.
For executing experiments, I primarily used the command line, which provided the flexibility and control needed for my workflows. When working with large-scale setups, I often configured clusters of nodes to support distributed computing. Chameleon made it straightforward to establish distributed file systems like BeeGFS or NFS across multiple nodes, as well as set up distributed memory caches using KV stores like Redis.
Chameleon's bare-metal reconfiguration capabilities provided full control over the software stack, including root privileges, kernel customization, and console access. For instance, many of my experiments required root privileges to install and configure critical components, such as specific CUDA versions for PyTorch-based deep learning frameworks or custom file systems for building tailored clusters. This level of control allowed me to precisely optimize the environment for my experiments, ensuring accuracy and reproducibility.
Without Chameleon, setting up these experiments on private, college, or national lab cloud infrastructures would have been significantly more challenging and expensive. Most of these cloud platforms do not offer the same degree of low-level control, often requiring workarounds or compromises in the experimental design. This limitation would not only increase costs but also introduce potential inefficiencies in replicating real-world scenarios. Chameleon's capabilities also streamlined the process of testing and iterating on hypotheses as it allowed me to spend time on thinking rather than worrying about potential costs that I am incurring every minute. In the absence of Chameleon, I might have been forced to modify my hypotheses or experimental setups to fit the constraints of other platforms to lower costs, potentially altering the scope and scale of my research.
For researchers looking to use Chameleon, I recommend leveraging its rich documentation and responsive support team, which are invaluable for troubleshooting and optimizing experiments. The platform's flexibility and robust infrastructure make it an exceptional resource for conducting cutting-edge research.
Experiment Artifacts
Our work was recently published at the 15th ACM Symposium on Cloud Computing, SoCC'24. The full paper and code along with a detailed walkthrough regarding experiment reproduction are available online.
User Interview

Tell us a little bit about yourself
I am currently in the final year of my PhD program in Computer Science at Virginia Tech. As a researcher in ML Systems, my mission is to transform how AI workloads are managed, ensuring they are efficient, scalable, and equitable. My work focuses on designing adaptive, resource-aware AI systems that bridge the gap between application needs and system constraints. Specifically, I lead efforts to: (1) Develop intelligent caching techniques to mitigate I/O bottlenecks in distributed ML training/inference, ensuring efficient data access and maximizing GPU utilization, and (2) Design ML-driven resource management frameworks that integrate advanced scheduling algorithms and adaptive resource allocation strategies to reduce waste, improve performance, and ensure fair and efficient model serving across diverse workloads and user applications. In my spare time, I enjoy going outdoors, hiking, swimming, or socializing over a cup of tea or coffee. I also enjoy documentaries, geopolitics, and thought-provoking novels or articles. I keep my website (https://rkhan055.github.io/) updated with the latest news, so feel free to reach out if you have any questions or would like to connect!
Most powerful piece of advice for students beginning research or finding a new research project?
One piece of advice I'd give to students starting research is: Curiosity is your compass, persistence is your fuel, and collaboration is your strength.
Begin by following your curiosity---find questions that ignite your passion, not just what's popular. The most impactful breakthroughs often come from asking bold, unpolished questions---ones others overlook or dismiss. Let your curiosity guide you to explore the 'why' and 'how' of problems. But remember, research is not also a solo journey. The best discoveries emerge from collaboration and teamwork. Seek mentors, peers, and communities who can challenge and inspire you. Share your ideas, embrace feedback, and build on the collective knowledge of others.
Explore fearlessly. Play around with open-source artifacts, experiment, and don't be afraid to fail. Failure isn't the opposite of success---it's part of the path to it. Every failed attempt is a step closer to clarity and innovation. Challenges will test you: failed experiments, confusing data, or a reviewer who doesn't see your vision. But persistence transforms obstacles into stepping stones. Each setback is a lesson.
Finally, understand that impactful ideas take time. The breakthroughs shaping our modern world weren't crafted in a day---they grew from countless iterations, shared insights, and relentless effort. Connect your work to a larger purpose. How will your research help others, expand knowledge, or create opportunity? A meaningful 'why' will keep you motivated even on tough days.
In research, you're not just discovering answers---you're building the resilience, creativity, and focus that will shape your entire journey as a thinker and innovator. Dive in, stay curious, and embrace the process.
How do you stay motivated through a long research project?
I stay motivated through a long research project by anchoring my work to a larger purpose, embracing curiosity, and breaking the journey into manageable milestones.
First, I remind myself of the impact my research can have---how it could solve real-world problems, advance knowledge, or empower others. Knowing that my work contributes to something bigger than myself keeps me grounded and inspired.
Second, I lean into curiosity. Research is as much about the process as the outcome. I view challenges as puzzles to solve and setbacks as opportunities to learn something new. This mindset turns frustrations into fuel for discovery.
Finally, I break the project into smaller, achievable goals. Celebrating progress---whether it's solving a tricky problem, getting insightful results, or even just organizing my thoughts---gives me a sense of momentum and accomplishment.
Additionally, I make time to collaborate and share ideas with peers. Conversations and feedback energize me, often sparking fresh perspectives. And when things get tough, I remind myself that persistence, not perfection, is what drives innovation.
Staying motivated is about maintaining a balance between vision, curiosity, and the steady joy of progress.
Why did you choose this direction of research?
I chose this direction of research because AI systems are transforming industries and solving problems once thought insurmountable. From advancing precision medicine and combating climate change to revolutionizing education and industrial automation, AI's impact is immense and far-reaching.
However, as AI workloads grow more complex, they place enormous strain on the underlying distributed systems tasked with handling vast amounts of data, computational demands, and operational costs. This bottleneck threatens to limit AI's accessibility and scalability, raising an urgent question: How can we design AI systems that are efficient, scalable, and sustainable while remaining inclusive?
My research focuses on addressing this challenge, aiming to push the boundaries of what AI systems can achieve. By developing innovative solutions that improve scalability and resource efficiency, I hope to unlock AI's full potential, ensuring that these transformative technologies remain accessible to researchers, industries, and societies alike. To me, this work is about more than technology---it's about creating the foundation for equitable innovation that benefits everyone.
Thank you for sharing your knowledge with the Chameleon community!
Building MPI Clusters on Chameleon: A Practical Guide
Simplifying Distributed Computing Setup with Jupyter, Ansible, and Python
- Nov. 18, 2024 by
- Michael Sherman
Running distributed applications across multiple nodes is a common need in scientific computing, but setting up MPI clusters can be challenging, especially in cloud environments. In this post, we'll explore a template for creating MPI clusters on Chameleon that handles the key configuration steps automatically, letting you focus on your research rather than infrastructure setup.
High-Performance Federated Learning Systems
- May 17, 2021 by
- Zheng Chai
This work is part of George Mason University PhD student Zheng Chai and Prof. Yue Cheng’s research on solving federated learning (FL) bottlenecks for edge devices. Learn more about the authors, their research, and their novel FL training system, FedAT which already has impressive results, improving prediction performance by up to 21.09% and reducing communication cost by up to 8.5 times compared to state-of-the-art FL systems.
No comments