If At First You Don't Succeed, Try, Try, Again...? Insights and LLM-Informed Tooling for Detecting Retry Bugs in Software Systems
Using Chameleon to Hunt Down Elusive Retry Bugs in Software Systems
- Oct. 21, 2024 by
- Bogdan-Alexandru Stoica
Have you ever refreshed a webpage when it did not load correctly the first time, and it worked on the second try? Software systems often use a similar approach called "retry," where they automatically attempt an operation again after a failure.
Hence, retry is a fundamental functionality in software systems that enhances resilience by automatically re-executing failed operations. It is important because many failures in software systems are transient and can be resolved simply by executing the operation again. Implementing retry logic is challenging due to the diversity of failure conditions and the need to decide when and how to retry appropriately. The complexity arises from the fact that not all failures are transient; indiscriminate retries can lead to resource exhaustion or cascading failures. Additionally, retry logic must handle state management, error classification, and timing considerations, which can be difficult to implement correctly.
Testing retry functionality is equally challenging because it requires simulating rare, transient errors that are hard to reproduce in controlled environments. Achieving sufficient code coverage to expose issues in retry logic demands specialized tests that can faithfully recreate these conditions. Traditional program analysis methods struggle to identify where retry logic is implemented because it often relies on non-structural elements like comments, variable names, and error messages rather than explicit code structures. In this context, our work focuses on overcoming these challenges by combining software testing, traditional program analysis, and large language models to effectively detect and analyze retry functionality in software systems.
Research Overview
To understand the challenges of detecting retry bugs, our research began with a systematic study of known retry-related failures in software systems. By analyzing these incidents, we extracted common failure patterns and symptoms that informed the design of Wasabi, our detection tool.
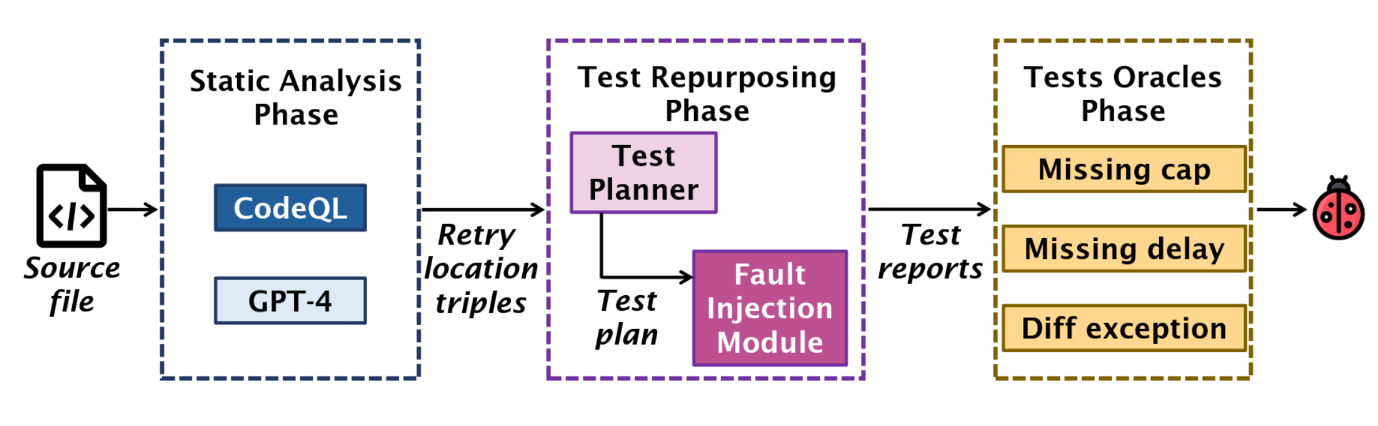
The key components of our approach involve the following core ideas:
- How to trigger retry? We use fault injection to strategically throw retry-triggering exceptions at specific points in the code where retry logic could be activated. This simulates the rare, transient errors that are difficult to reproduce in standard testing environments.
- Where are these retry locations? We use a combination of traditional static code analysis and large language models. While static analysis helps identify retry implementations based on code structure, language models excel at fuzzy code comprehension tasks and provide a semantic understanding by interpreting code comments, variable names, and log messages, which are often better indicators of retry functionality than structural elements.
- How to steer program execution towards these retry locations? Instead of implementing new tests from scratch, we repurpose existing unit tests. These tests already cover significant portions of the codebase, including areas where retry functionality may reside. By augmenting them with fault injection, we can effectively reach and test the identified retry locations.
- How to determine if a retry bug has occurred? We design specialized test oracles tailored to detect retry-specific symptoms uncovered in our bug study. These include indicators such as unbounded retry attempts, retries occurring without appropriate delays, and improper state management between retry attempts.
Experimental Implementation on Chameleon
Evaluating the efficacy of Wasabi requires precise control over the testing environment to accurately detect retry bugs in complex software systems. We used Chameleon to create a customized infrastructure that mirrors real-world deployment conditions. Specifically, we deployed Wasabi on Chameleon's bare-metal nodes to ensure full control over system configurations and resources.
Our experiment provisions bare-metal instances with the necessary hardware specifications, like specific CPU, memory, and storage capacity, tailored to handle large codebases such as those in the Apache suite (Hadoop, HBase, Hive, etc.). Using Chameleon's command-line interface, we automated the deployment process, allowing us to seamlessly replicate this environment across multiple nodes.
To instrument the target applications with Wasabi, we use Chameleon's root access permissions to modify system configurations and access rights. Running experiments involve setting up the workspace, installing dependencies, and integrating our tool with the build systems of the target application.
The hardware catalog and host availability browser were the key features that helped us quickly identify appropriate nodes that met our requirements. We also leveraged Chameleon's support for custom kernel booting to install specific kernel versions and dependencies needed by the target applications we tested. This capability was crucial for reproducing the exact conditions under which retry bugs manifest.
Key features of Chameleon that were essential for running Wasabi include bare-metal reconfiguration and the ability to perform custom kernel boots.
Our tool requires specific system setups and root access rights, which aren't typically available on standard cloud platforms. Chameleon's support for direct hardware access allowed us to replicate complex environments necessary for detecting retry bugs effectively. Without Chameleon, reproducing these conditions would have been significantly more laborious and could have limited the scope of our research.
Experiment Artifacts
Our work was recently published at the 30th Symposium on Operating Systems Principles, SOSP’24. The full paper, code, and a podcast where my advisor—Shan—and I talk about the core ideas behind retry bug finding are available online:
- Paper: https://bastoica.github.io/files/papers/2024_sosp_wasabi.pdf
- Code: https://github.com/bastoica/wasabi/
- Podcast: https://www.microsoft.com/en-us/research/podcast/abstracts-november-4-2024/
User Interview

Tell us a little bit about yourself
I am a PhD candidate at the University of Chicago where I build software analysis tools to help developers better reason about tier code. My research interests revolve around software testing, monitoring, and tracing; efficient code instrumentation; program analysis; and machine learning data-driven techniques (e.g., large language models).
In a previous life, I had a grown-up job as a software engineer where I most often faced challenges with failures reproducibility. These early struggles motivated me to follow a research career path to find new, creative ways to tackle such obstacles.
Thank you for sharing your knowledge with the Chameleon community!
ALERT: Accurate Anytime Learning for energy and timeliness in software systems
- Oct. 18, 2021 by
- Chengcheng Wan
Learn about University of Chicago PhD student Chengcheng Wan's research on designing a solution to integrate machine learning components into traditional software systems to maximize energy efficiency, latency, and accuracy constraints at machine learning, system and application levels, with related research published at USENIX ATC, ICML, and ICSE.
Software Defined Networking with OpenFLow on Chameleon
- Aug. 17, 2018 by
- Paul Ruth
Chamaleon now supports isloated OpenFlow experiements controlled by users. This tips blog post shows you how to get started using OpenFlow on Chameleon.
No comments