Design Considerations and Analysis of Multi-Level Erasure Coding in Large-Scale Data Centers
Revolutionizing Data Storage with Multi-Level Erasure Coding
- Dec. 11, 2023 by
- Meng Wang
Disk failures are common in storage systems, which can result in data loss. To mitigate this risk, people often employ data redundancy strategies, similar to keeping backups of important documents at home. However, maintaining multiple copies of data can be costly in terms of disk space. To address this, erasure coding (EC) is used. For example, consider two data numbers, A = 1 and B = 2. With erasure coding, you can compute a parity value, P = A + B = 3. If the disk storing number A fails, you can reconstruct its value by performing the reverse computation: A = P - B = 3 - 2 = 1.
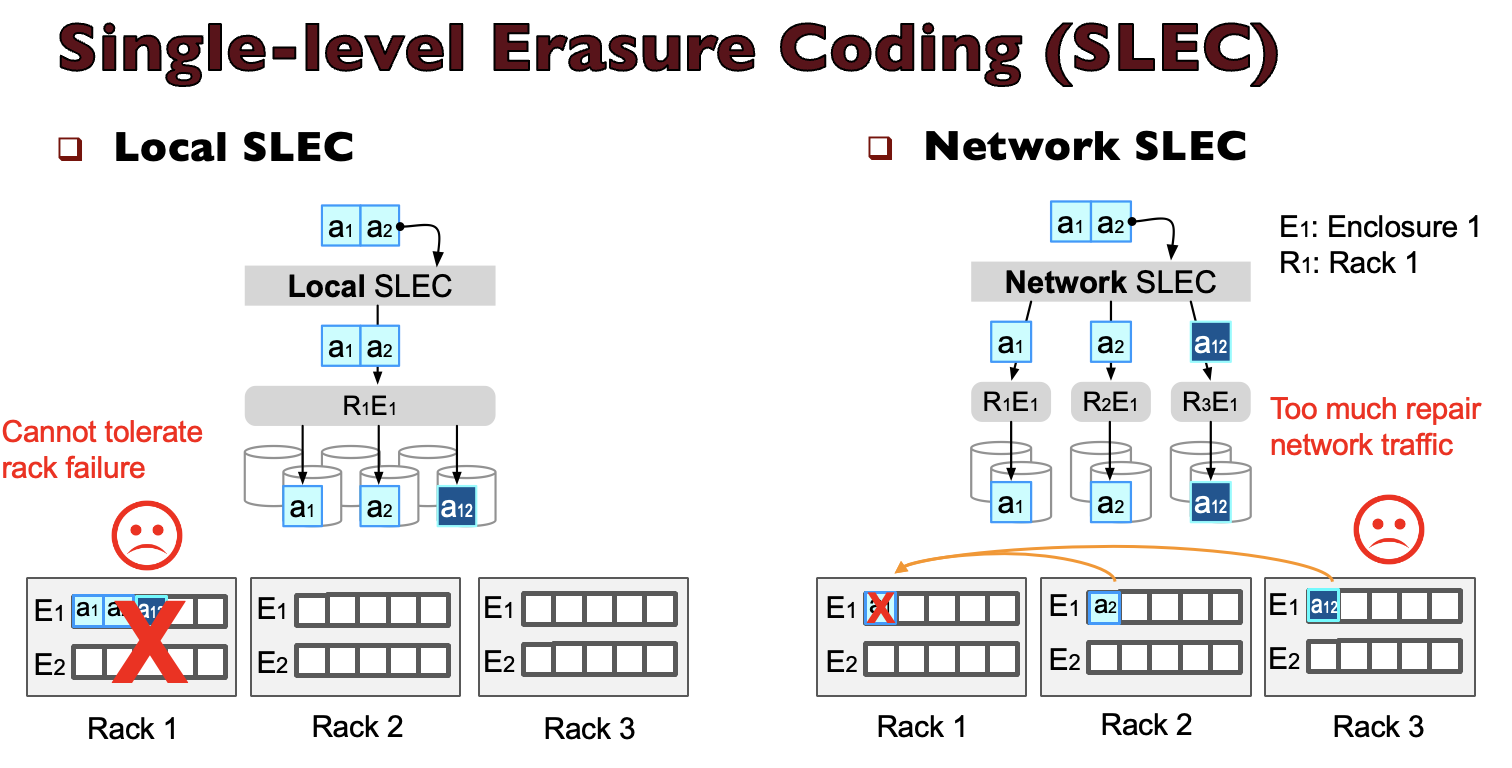
Modern data centers are typically hierarchical, consisting of multiple racks, each housing hundreds of disks. These data centers commonly employ single-level erasure coding (SLEC) for data protection, with the choice between local-only SLEC within racks or network-only SLEC across racks. However, for managing tens or hundreds of thousands of disks, the classic SLEC no longer scales and cannot provide a good balance between minimizing encoding/repair overhead and maximizing rack/enclosure-level failure tolerance. To overcome these limitations, practitioners have started to deploy multi-level erasure coding (MLEC), which performs EC at both network and local levels. The figure above and below illustrate the workflow of SLEC and MLEC, respectively.
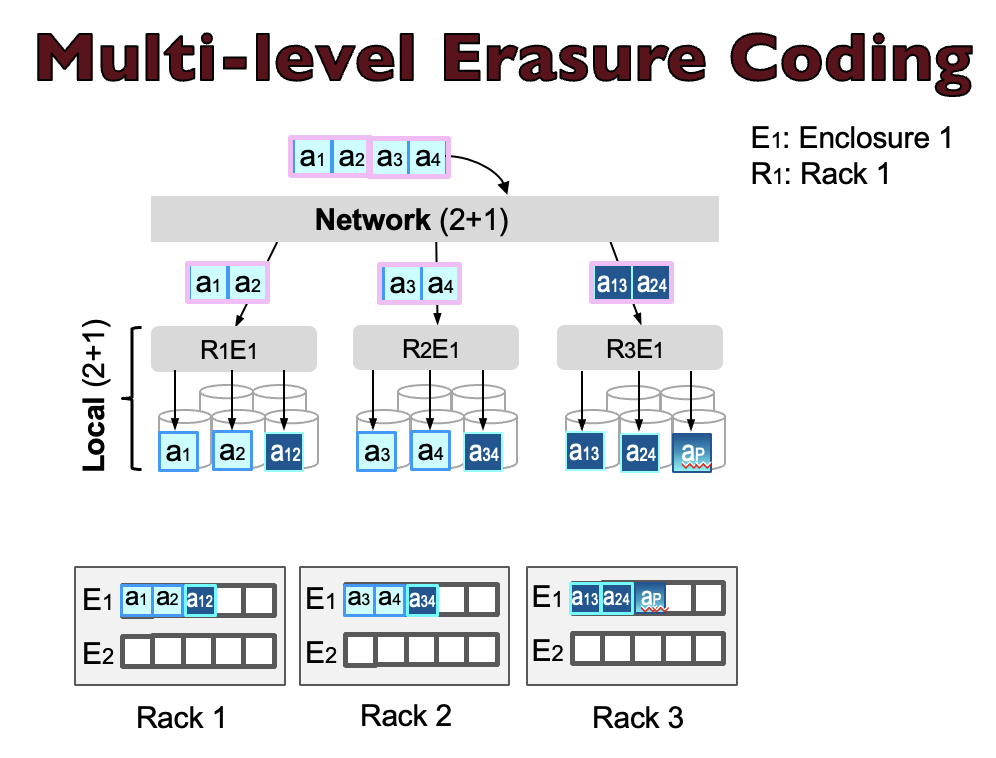
While MLEC seems promising, there is no in-depth study of design considerations for using it at scale. Many research questions remain unanswered. For example, what are the possible chunk placement schemes for MLEC at scale? What are their pros and cons in terms of performance and durability? What are the types of failure modes an MLEC system can face? Can we introduce advanced repair methods that are optimized for every specific scheme and failure mode? What are the implementation requirements for advanced repairs? Though other work analyzes hierarchical RAID (Redundant Array of Inexpensive Disks) for small-scale systems, we have not seen any work answering the questions above or studying design considerations of MLEC for large-scale systems.
Our Research Findings
In our research, we provide, to the best of our knowledge, the most comprehensive design considerations and analysis of MLEC at scale that addresses the questions above. More specifically, we present the following contributions.
- We introduce the design space of MLEC in multiple dimensions, including various code parameter selections, chunk placement schemes, and various repair methods from a simple and practical one to a more optimized one that leverages the multi-level EC but requires cross-level transparency.
- We quantify their performance (encoding throughput, repair network traffic, repair time, etc.) and durability (under independent and correlated failures). We show which MLEC schemes and repair methods can provide the best tolerance against independent/correlated failures and reduce repair network traffic by orders of magnitude.
- To achieve all of the above, we use various evaluation strategies including simulation, splitting, dynamic programming, and mathematical modeling. We build, to the best of our knowledge, the first sophisticated MLEC simulator (in almost 13,000 lines of code (LOC)) that allows us to measure MLEC performance and durability at scale (over 50,000 disks), with many capabilities such as simulating disk failures (based on distributions, rules, or real traces), combining multi-level clustered/declustered placements, expressing failure tolerance, and executing complex repairs.
- We also compare the performance and durability of MLEC with other EC schemes, including SLEC and state-of-the-art EC techniques like LRC (Local Reconstruction Codes). Our results show that MLEC can provide high durability with higher encoding throughput and less repair network traffic than both SLEC and LRC.
Configuring or extending an MLEC design at extreme scales can be costly without proper understanding of the implication of the proposed changes. We hope our analysis (along with the simulation code and evaluation artifact that we have released) will enable engineers and operators of extreme-scale EC systems to have a comprehensive knowledge of the (dis)advantages of various MLEC schemes. We believe our findings will provide guidance for large-scale storage architects to choose ideal configurations for their particular environments and requirements.
Running the Experiment on Chameleon
We use simulations to evaluate the durability of erasure-coded systems. However, to estimate high durability, a simulation must run a large number of iterations to capture even one system data loss event, which is very time-consuming. In order to speed up the simulation, we ran the simulation using multi-processing. Thanks to Chameleon’s powerful machines, such as the compute_zen3 node which contains 256 CPU threads and 256GB RAM, we were able to save a lot of time by running more 200 iterations in parallel. I did the coding using VSCode, which can be easily connected to Chameleon nodes using ssh via the floating IP, and I ran the experiments using the command line in VSCode.
Chameleon also made it easy to share our experiment and results. I used Chameleon's integration with Jupyter to create a Trovi artifact replicating some of the paper's visualizations. Jupyter's interface is user-friendly and makes it easy for others to reproduce my experiments. The Markdown texts are easy to read, and users can execute my commands with a single click. I also find Chameleon’s hardware catalog helpful for me to find powerful machines to run simulations. I also use the host availability browser regularly to find available nodes.
If Chameleon was not available, I would have had to run the simulations on my own computer with a small number of CPU threads. It would have been much harder and easily would have taken me ~20x the amount of time to finish the simulations. Many thanks to Chameleon’s powerful machines!
Interview with Meng Wang

Q: Tell us about yourself!
I am a Ph.D. candidate in the Department of Computer Science at the University of Chicago under the guidance of Professor Haryadi S. Gunawi. My research focuses on enhancing the performance and dependability of storage systems, with a primary emphasis on three areas:
- Firstly, I aim to improve the system performance stability by mitigating tail latencies in cloud storage systems.
- Secondly, I specialize in designing and analyzing erasure coding techniques to improve the fault tolerance of large-scale storage systems.
- Lastly, I am working on optimizing the storage layer of machine learning training systems.
Q: How do you stay motivated through a long research project?
I believe it’s important to start from simple and not to be too aggressive at the beginning. When faced with a large and complicated project, I usually break it down into small sub-problems. Initially, I opt for simple and straightforward solutions, which give me a good start. Subsequently, I address any challenges or issues that arise from these initial solutions, and incrementally enhance, ultimately arriving at a robust and effective solution. By following this approach, I continually find motivation in overcoming small challenges, which bolsters my confidence throughout the duration of a long research project.
Challenges are opportunities. When you encounter challenges or problems during your research, don't be discouraged. These challenges will become valuable additions to your paper, making it stronger. You can start by addressing the challenges in simpler cases, and then work your way to more complex ones. While you may not find a perfect solution, an effective one for multiple common cases is already a significant contribution in itself.
Q: Are there any researchers you admire? Can you describe why?
Yes. Actually there are quite a few researchers that I admire, but here I’d like to mention two in particular:
My advisor Haryadi Gunawi, who guided me through my research and gave me tons of suggestions.
My collaborator and internship supervisor John Bent, who taught me a lot not only in research, but also in shaping my career.
Q: Why did you choose this direction of research?
I find great enjoyment in hacking and optimizing the source codes of complex systems; it's truly a rewarding and enjoyable experience.
Thank you for sharing your knowledge with the Chameleon community!
No comments