Tensor Analysis
- Jan. 17, 2023 by
- Mao-Lin Li
What is the central challenge/hypothesis your experiment investigates?
Tensor representation is commonly used for multi-modal and multi-dimensional data sets. For example, in order to understand the shopping behavior of Amazon’s consumers, we can analyze the transaction data. We can extract “consumer” and “item” from the transaction data as a 2-D zero-one matrix (if the consumer purchased the item, mark [i,j]=1 in the matrix; otherwise, [i,j]=0). We can also include the transaction time and make it a 3-D matrix. Those matrices are called tensors, and the attributes of the matrix (in our case, consumer, item, and transaction time) are called tensor mode. Tensor decomposition is any scheme for expressing a tensor as a sequence of elementary operations acting on others and thus helping extract important information from a tensor. There are a lot of tensor decomposition algorithms and Tucker is one of the most commonly used algorithms. The disadvantage of the Tucker algorithm is that memory and computation effort grows exponentially with the number of tensor modes. The tensor train (TT) algorithm solves the problem by using an approximated representation which requires lesser space and decomposition time. TT-decomposition has been widely used in deep learning, crowdsourcing, and recommendation systems. However, finding an optimal sequence for TT decomposition is not trivial. For a 4-mode tensor, there are 4!=24 possible decomposition sequences and it’s impractical to enumerate all of them to choose the best sequence. Therefore, identifying the best decomposition sequence efficiently and effectively becomes important.
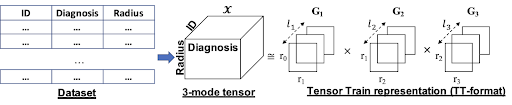
How is your research addressing this challenge?
In order to identify an optimal decomposition sequence, we developed an algorithm called Guiding the Tensor Train (GTT). GTT leverages various data characteristics, such as the number of modes, length of the individual modes, density, distribution of mutual information, and distribution of entropy, to pick a decomposition sequence.
How do you structure your experiment on Chameleon?
We used KVM@TACC for our experiments with the GUI interface and OpenStack APIs. We used the GUI interface for initial setups and package installations. We “saved” our manual setups by taking a snapshot and creating a customized image. Then, this customized image was used for creating multiple instances - each of the instances was responsible for calculating one metric described in the previous question. We also enabled an SFTP port for each instance for data loading and communications. There was a special instance called aggregation instance which was responsible for collecting results from all metric calculating instances and outputting the final result.
What features of the testbed do you need in order to implement your experiment?
We rely on the GUI interface which allows us to easily set up our experiment with the desired number of CPUs, size of memory and storage, and third-party packages.
Why did you choose this direction of research?
I was interested in social network analysis and recommendation systems before I joined ASU, since I wanted to know how people interact with each other and how I could know what people like. These topics motivated me to seek more fundamental knowledge during my PhD. I am focusing more on the hidden semantics in the data, which we try to extract the most significant information from high-dimensional data in the real world and further analyze it to achieve effective decision-making.
Most powerful piece of advice for students beginning research or finding a new research project?
- Plan ahead even though life is so unpredictable.
- Believe in yourself.
Are there any researchers you admire? Can you describe why?
I was lucky enough to get supervision from Dr. Candan when I joined ASU, and had the opportunity to dig into the fundamental areas for my research. Dr. Candan is an enthusiastic researcher and willing to devote a lot of time to his students, and always gives insightful advice for our research. He is really a nice supervisor to teach me how to do decent research.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
- Mao-Lin Li, K. Selçuk Candan, Maria Luisa Sapino. GTT: Leveraging data characteristics for guiding the tensor train decomposition, Information Systems, Volume 108, 2022, ISSN 0306-4379, https://doi.org/10.1016/j.is.2022.102047. https://www.sciencedirect.com/science/article/pii/S0306437922000424
- Youtube video for GTT presentation in SISAP 2020 [Best Paper Candidate]: https://youtu.be/lxy1rbK3sv8
Authors

Mao-Lin Li is a PhD candidate at the School of Computing and Augmented Intelligence (SCAI) at Arizona State University. His research interests include management and analysis of imprecise, high-dimensional data, with applications including collaborative filtering and predictive analysis.

K. Selcuk Candan is a professor of computer science and engineering at Arizona State University (ASU) and the director of ASU’s Center for Assured and Scalable Data Engineering (CASCADE). His primary research interest is in the area of decision making through efficient and trusted management and analysis of non-traditional, heterogeneous, and imprecise (such as multimedia, web, and scientific) data, with applications in human centered complex systems, such as pandemics and disaster preparedness and response, building energy systems, and sustainability.

Hans Behrens is a PhD Candidate at the School of Computing and Augmented Intelligence (SCAI) at Arizona State University. His research focuses on the intersection of data science, distributed computing, network security, and resilient design.

Maria Luisa Sapino is a Professor of Computer Science at University of Turin and an Adjunct Professor at Arizona State University. Her major research interests are in the area of Heterogeneous and Multimedia Data management, with strong emphasis on tackling the so called "Big Data challenges", including aspects related to the development of efficient techniques for tensor based big data analysis, and on various aspects related to indexing, classification and querying of (possibly multivariate) time series. Maria Luisa Sapino is active in multiple interdisciplinary projects, in which different domains and disciplines, apparently far from each other (such as Building Energy Consumption Analysis and Study of the Infectious Disease Propagation) can benefit from "smart data oriented" fundamental technological innovations.

Fateh Singh is a Computer Science Master’s student and a graduate research assistant at Arizona State University. My interest area is in the field of highly scalable and performant distributed systems. I wish to start a tech startup and carry out philanthropic activities sometime in the future. My hobbies include playing basketball and traveling.
LinkedIn: https://www.linkedin.com/in/singh-fateh/
Acknowledgments: We like to acknowledge the contributions of numerous other team members, including Javier Redondo Antón, Fahim Tasneema Azad, Xilun Chen, Gerardo Chowell-Puente, Ashish Gadkari, Yash Garg, Xinsheng Li, Sicong Liu, Giulia Pedrielli, Silvestro Roberto Poccia, Md Shadab, Dalton Turner, Magesh Vijayakumaren.
No comments