Large Scale Ensemble Simulations
- Aug. 15, 2022 by
- Hans Behrens
What is the central challenge/hypothesis your experiment investigates?
The first challenge our team is focused on is leveraging Chameleon to develop a novel data platform for running large scale and coupled simulations. The platform (DataStorm) helps researchers from diverse domains working independently on different models to seamlessly integrate their work and define model interactions (in the form of a directed acyclic graph consisting of models) and to develop insights into these complex interactions via a single user interface with easily configurable execution settings. Each of these models may operate at different spatial and temporal resolutions so integrating these models into a single execution becomes very complex and requires heavy engineering. Take simulation to understand the development of immunity in a community during a pandemic as an example. A human behavior analyst builds models to understand the effect of weather changes on the movement of people; a pandemic specialist develops models to understand how pandemics spread when the movement of people changes; and an immunology specialist develops models to estimate immunity characteristics based on the spread of a pandemic. There may be more components and complex interactions evolved over time in the system. Therefore, an easy-to-use platform enabling researchers to collaborate and achieve deep actionable insights is desired.
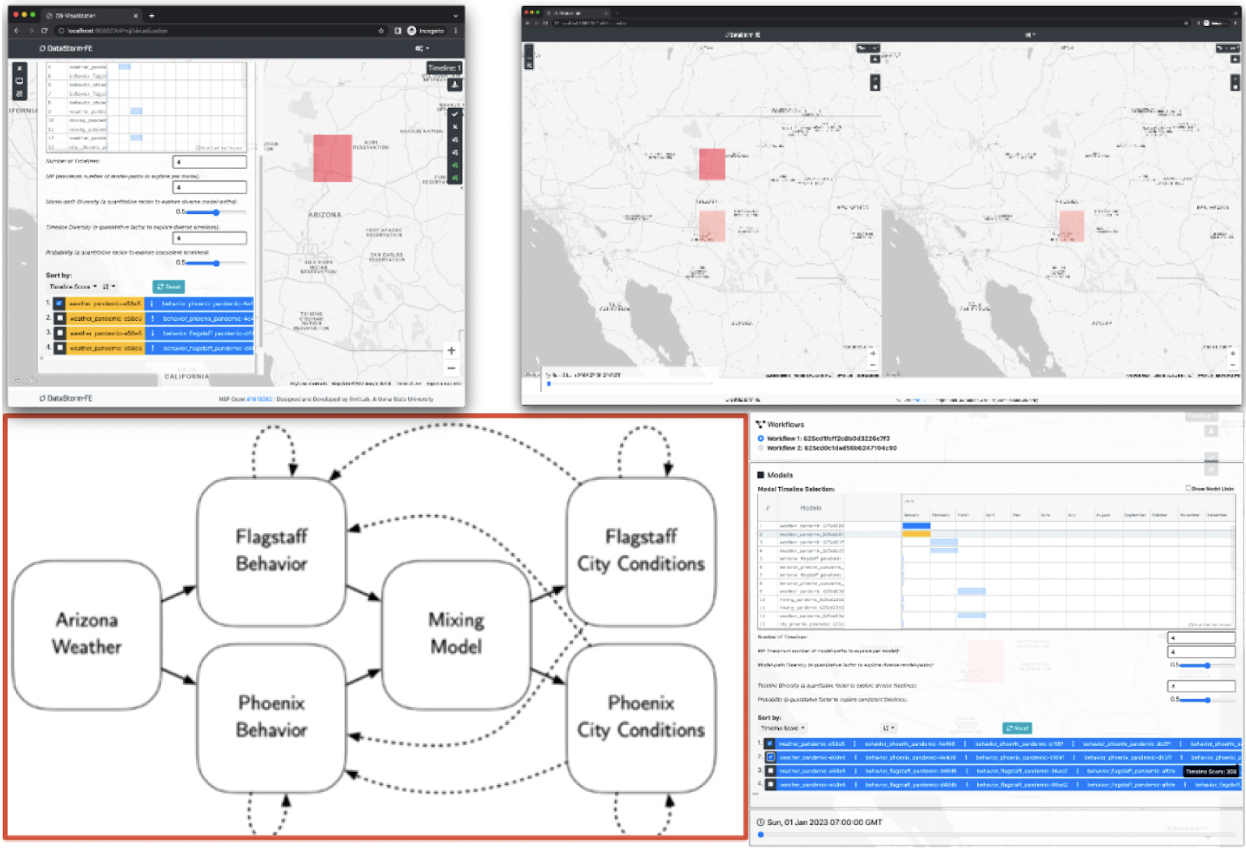
How is your research addressing this challenge?
Our data platform, DataStorm, provides a highly configurable interface which allows users to define the models in the execution graph and define the spatial temporal and spatial resolution that each of the models operates upon. The platform automatically applies the required temporal and spatial transformations to the data to satisfy each of the models, thus eliminating manual data manipulation from the execution pipeline. DataStorm also enables parameter-space sampling to decide which simulations to execute and which simulation results to save with given criteria. The data platform allows users to save model states and data with timestamps and provides default model outputs when data is not available. The platform also allows users to execute multiple workflows at the same time so that the users can compare the results via the visualization interface. In addition, users can easily deploy their models and dependencies to Chameleon with the platform (see next question). To summarize, domain scientists can collaborate and deploy their models using our easy-to-use highly performant platform.
How do you structure your experiment on Chameleon?
We use KVM@TACC for our experiments with OpenStack APIs. An orchestration instance was used to automate the deployment and configuration of the platform. The core instances include (1) a database instance which is responsible for storing and providing data to each of the models, (2) a visualization instance which is responsible for providing the required data to the user interface, and (3) a runtime instance which is responsible for coordination, execution, and state management of models for the simulation. The system is scalable with worker instances. Each worker instance is launched dynamically and corresponds to a model that is part of the execution graph. The platform would guide the users to configure their experiments. The worker instances interact with each other through the runtime instance and the database instance via asynchronous and continuous executions. We used Python scripts, Ansible, and OpenStack SDK for the deployment and configuration of the system. (see artifact question)
What features of the testbed do you need in order to implement your experiment?
Chameleon KVM site allows us to quickly and dynamically scale up and down our system in order to satisfy the users’ needs of creating large complex execution graphs. Our system is built based on OpenStack SDK and python clients which provide easy ways to use and manage Chameleon resources. By building DataStorm on top of the industry-standard OpenStack technology supported by Chameleon, we are also enabling users to eventually port the DataStorm platform to their own clusters.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
- Hans Walter Behrens, K. Selçuk Candan, Xilun Chen, Yash Garg, Mao-Lin Li, Xinsheng Li, Sicong Liu, Maria Luisa Sapino, Md Shadab, Dalton Turner, Magesh Vijayakumaren: DataStorm: Coupled, Continuous Simulations for Complex Urban Environments. Trans. Data Sci. 2(3): 19:1-19:37 (2021)
- DataStorm public releases: https://github.com/EmitLab/DataStorm-Release
- PanCommunity/DataStorm overview: https://youtu.be/huBC-mP-0FI
Tell us a little bit about yourself

Hans Behrens is a PhD Candidate at the School of Computing and Augmented Intelligence (SCAI) at Arizona State University. His research focuses on the intersection of data science, distributed computing, network security, and resilient design.

K. Selcuk Candan is a professor of computer science and engineering at Arizona State University (ASU) and the director of ASU’s Center for Assured and Scalable Data Engineering (CASCADE). His primary research interest is in the area of decision making through efficient and trusted management and analysis of non-traditional, heterogeneous, and imprecise (such as multimedia, web, and scientific) data, with applications in human centered complex systems, such as pandemics and disaster preparedness and response, building energy systems, and sustainability.

Mao-Lin Li is a PhD candidate at the School of Computing and Augmented Intelligence (SCAI) at Arizona State University. His research interests include management and analysis of imprecise, high-dimensional data, with applications including collaborative filtering and predictive analysis.

Maria Luisa Sapino is a Professor of Computer Science at University of Turin and an Adjunct Professor at Arizona State University. Her major research interests are in the area of Heterogeneous and Multimedia Data management, with strong emphasis on tackling the so called "Big Data challenges", including aspects related to the development of efficient techniques for tensor based big data analysis, and on various aspects related to indexing, classification and querying of (possibly multivariate) time series. Maria Luisa Sapino is active in multiple interdisciplinary projects, in which different domains and disciplines, apparently far from each other (such as Building Energy Consumption Analysis and Study of the Infectious Disease Propagation) can benefit from "smart data oriented" fundamental technological innovations.

Fateh Singh is a Computer Science Master’s student and a graduate research assistant at Arizona State University. My interest area is in the field of highly scalable and performant distributed systems. I wish to start a tech startup and carry out philanthropic activities sometime in the future. My hobbies include playing basketball and traveling.
Acknowledgments: We like to acknowledge the contributions of numerous other team members, including Javier Redondo Antón, Fahim Tasneema Azad, Xilun Chen, Gerardo Chowell-Puente, Ashish Gadkari, Yash Garg, Xinsheng Li, Sicong Liu, Giulia Pedrielli, Silvestro Roberto Poccia, Md Shadab, Dalton Turner, Magesh Vijayakumaren.
Most powerful piece of advice for students beginning research or finding a new research project?
- Building your network is a critical aspect of research – finding new collaborators should start on day one.
- Related to the above, don't be afraid to ask for help! Chances are that your colleagues (both peers and mentors) have experienced similar challenges before, and will have useful advice to offer.
How do you stay motivated through a long research project?
Personally, I find that working on two or three projects at once can help with this, because you can inject variety into your tasks by switching projects when you're deadlocked or waiting. Banging your head against a problem without a break is almost never the right answer.
Have you ever been in a situation where you couldn’t do an experiment that you wanted to do? What prevented you from doing it?
At one point, I needed to measure the efficiency of my proposed approach, but found that it was difficult to represent in a closed form. I thought it might be easier to test it empirically, but since the target devices were extremely low-power embedded devices, the difference in power consumption was on the order of joules. The hardware needed to test at that level of sensitivity was impractical for generating a single result, and I, unfortunately, had to give up on that measurement.
No comments