Chameleon, and Simulating Self Propagating Malware to Evaluate Detection Technology
- July 25, 2022 by
- Jason Hiser
Experiment Section
What is the central challenge/hypothesis your experiment investigates?
One of our research goals at the University of Virginia (UVA) is to detect cyber attacks through analysis of network data across large, enterprise systems. To provide the necessary data for this research, UVA, along with its partner Virginia Tech (VT), are recording every network connection into and out of the two networks. To give an idea of the scale of the two networks, UVA has 22,000 students and 9,000 faculty and staff, and VT has 37,000 students and 13,000 faculty and staff. During one week in February 2022, 361 billion packets crossed the border which resulted in 14 billion unique connections being captured.
But, how do you develop and evaluate a new analytic on this data set without malware used to train machine learning models and evaluate the analytic?
How is your research addressing this challenge?
To get the data we need, we simulated full-scale attacks on our enterprise systems. Using our internal cloud-based compute systems, we create hundreds of virtual machines (VMs) that are vulnerable to the self-propagating malware, Mirai. We modified the Mirai malware such that it’s benign to common computers, but knows how to compromise our virtual machines.
To collect realistic data, the virus needs to do its malicious scanning, initial infection, binary download, and command and control activity from outside the enterprise. These steps are where Chameleon comes in.
How do you structure your experiment on Chameleon?
On Chameleon, we use the KVM dashboard to set up a Ubuntu virtual machine to host the Mirai binary downloads, to act as a server for command and control (C2), and to launch initial infections into our enterprise systems. We also set up a custom domain name server to serve malicious domains for our experiments.
Some of our experiments also involve simulating stealthy malware, where the C2 server changes IPs or domain names periodically. These experiments leverage Chameleon’s OpenStack API to dynamically change the networking components of the C2 servers and update the name server automatically. The malware then re-contacts the name server in order to re-contact the command-and-control server.
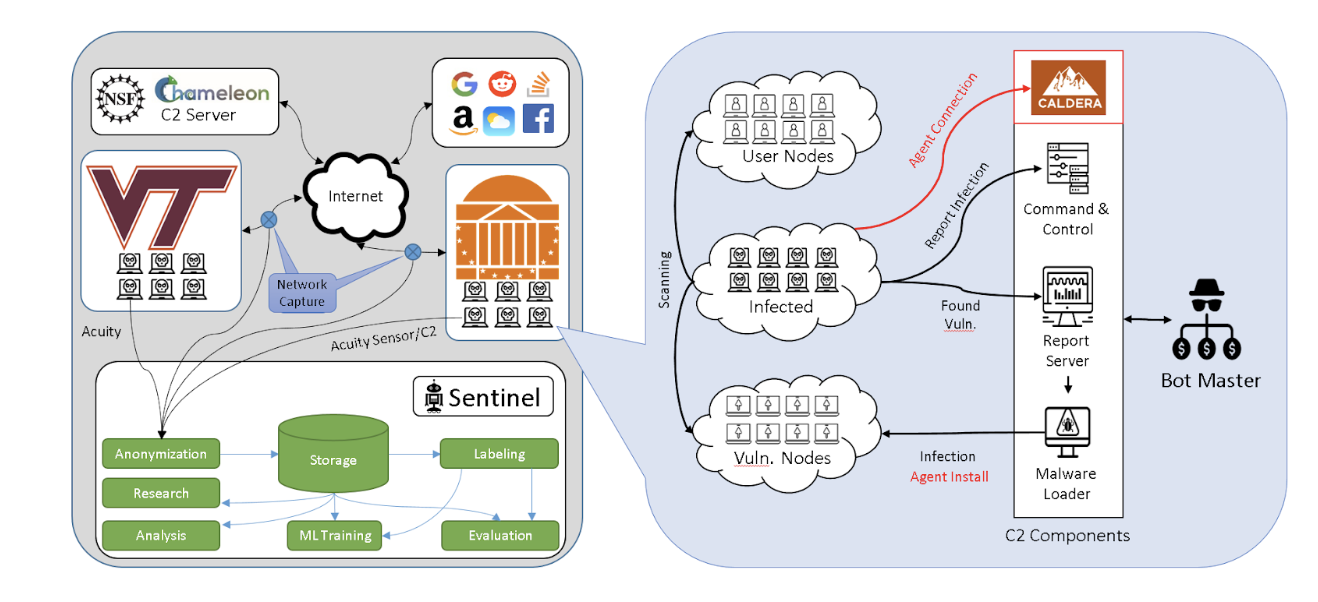
What features of the testbed do you need in order to implement your experiment?
The attack recreation we’ve performed on Chameleon have been hyper-realistic–real malware on a real network deployed safely. As such, we’ve set off every automatic malware detector you can imagine at UVA, VT, and Chameleon. Our #1 resource for dealing with these alerts is the Chameleon staff themselves. They’ve been excellent at working with us to allow these false alerts. They have been professional, courteous, prompt, and very helpful in navigating the safety and security policies needed to do this kind of attack recreation.
Furthermore, it’s been extremely useful to have the large pool of public IPs, such that each attack simulation can use a different IP address, such that machine learning algorithms don’t over-train for the IP address in question. Also, the bank of public IPs is useful with our shifting C2 simulations.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
Here are a few of the papers that describe the attack recreation and leverage the attack recreation infrastructure to use machine learning to detect attacks:
- PORTFILER: Port-Level Network Profiling for Self-Propagating Malware Detection. https://arxiv.org/abs/2112.13798
- CELEST: Federated Learning for Globally Coordinated Threat Detection. https://arxiv.org/abs/2205.11459
- On Generating and Labeling Network Traffic with Realistic, Self-Propagating Malware. https://arxiv.org/abs/2104.10034
Author Profile Section
Tell us a little bit about yourself

I’m Dr. Jason Hiser, a Principal Scientist with the University of Virginia. I have a Ph.D. in computer science. I’ve been leading the Attack Recreation track with the DARPA Cyber-hunting At Scale (CHASE) program. I also have a strong interest in reverse engineering of binary software, and have led the effort for the Zipr binary rewriter (https://git.zephyr-software.com/opensrc/zipr).
When I’m not working, I pedal bikes up the tallest, steepest mountains I can find.
Most powerful piece of advice for students beginning research or finding a new research project?
I regularly have an idea, work on it, and don’t publish because it feels too obvious, incremental or diminutive when I’m done. Then I see someone else publish the idea. If it’s new, publish it.
How do you stay motivated through a long research project?
Long research projects can definitely feel like a slog sometimes. Especially the late nights trying to get a publication polished and 100% ready for the horrors of peer review, or when you get those reviews back. What keeps me motivated in those moments? Knowing that science is how we know things, and publication and review is the backbone of the process. Especially in a world where fake news, pseudo-science, and woo is so common, it is incredibly motivating for me to know that this process is how the world really learns and grows as a species.
Why did you choose this direction of research?
I’ve been interested in how malware works, and how to detect it since I first heard about the concept in the ‘90s. At the time, I foolishly asserted you couldn’t put code in a .gif file. Since I learned how to do it, I’ve been thinking outside the box.
No comments