Exploring Process-in-memory Architecture for High-performance Graph Pattern Mining
- June 20, 2022 by
- Rujia Wang
Experiment Section
What is the central challenge/hypothesis your experiment investigates?
Bioinformatics, social network analysis, and computer vision are linked by the need to identify connections. Specifically, graph pattern mining (GPMI) need to find all subgraphs with different patterns that meet an application’s requirements, such as counting the number of 4-vertex connected subgraphs. 4-vertex connected subgraphs are subgraphs that contain 4 vertices and each vertex has edges to other 3 vertices. For example, in a social network, a 4-vertex connected subgraph refers to a group of people where each person knows each other. Such applications are considered a new class of data-intensive applications - they generate massive irregular computation workloads and pose memory access challenges, which degrade the performance and scalability significantly.
How is your research addressing this challenge?
Leveraging emerging hardware, such as process-in-memory (PIM) technology, could potentially accelerate applications like GPMI. PIM integrates processing units inside the memory to reduce the overhead of frequent data movement. Compared with CPU, PIM has more processing units and stronger computing power. In addition, PIM has higher bandwidth and lower latency to access memory, making it ideal for memory access-intensive applications such as GPMI. There are two most prominent memory technologies on PIM, Hybrid Memory Cube (HMC) and High Bandwidth Memory (HBM). Among them, the HBM-PIM is currently the most promising PIM hardware with its superior internal and external bandwidth. As shown in Figure 1, the HBM-PIM incorporates PIM cores inside of memory banks, and the PIM cores access the memory banks with different access paths (the arrows in Figure 1(b)).
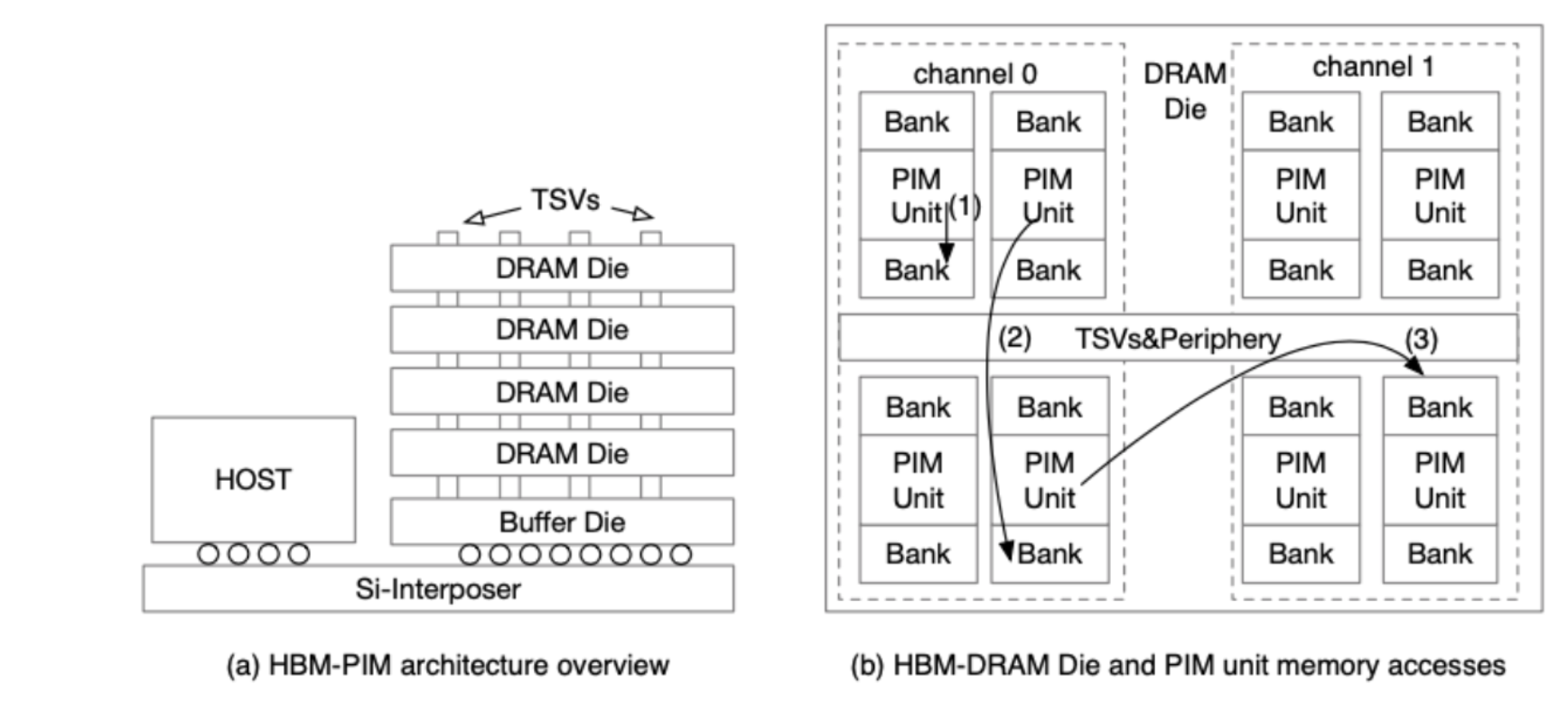
Figure 1: HBM-PIM architecture and internal bank organization.
In this project, we use PIM architecture to accelerate data-intensive operations in graph mining tasks. We first identify the code blocks that are best suitable for PIM execution. Then, we observe a significant load imbalance on PIM architecture and analyze the root cause for such imbalance in graph mining applications. Lastly, we evaluate several data placement and scheduling schemes that help reduce the load imbalance and discuss potential optimizations to enhance overall performance further. With our optimizations, GPMI applications could leverage general purpose PIM architecture for performance acceleration and save computation energy significantly.
How do you structure your experiment on Chameleon?
In our experiment, we use Cascade Lake R (CPU) nodes on CHI@UC. We run our baseline GPMI systems on Cascade Lake R nodes. For our graph mining applications on process-in-memory architecture, we use ZSim and Ramulator to simulate PIM systems on Cascade Lake R nodes.
What features of the testbed do you need in order to implement your experiment?
Since the execution time of the simulator is long and the simulated time is not related to the node performance, we use multiple nodes on Chameleon to run our graph mining applications on PIM architecture with different graphs at the same time. This is possible because Chameleon provides a lot of computing resources, so being able to run experiments simultaneously greatly reduces the time I spend running experiments.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
Our preliminary paper was published on https://ieeexplore.ieee.org/abstract/document/9511207. The full version of this work is currently under review.
Author Profile Section
About the Authors

Jiya Su is a Ph.D. student at Illinois Institute of Technology, working with Dr. Rujia Wang. She completed her master’s degree at Illinois Institute of Technology, and her bachelor's degree at Renmin University of China. Her research interests involve Processing-In-Memory, computer architecture and parallel and distributed computing.

Dr. Rujia Wang is an assistant professor of the Department of Computer Science at Illinois Institute of Technology. Her research involves designing secure and reliable memory architectures for future computing systems. Her interests span multiple areas including novel memory architecture, secure computing architecture, system reliability and high-performance computing.
Most powerful piece of advice for students beginning research or finding a new research project?
For students just beginning their research, finding an advisor who is relevant to their research interests is critical. A good advisor can help students quickly understand the flow of research.
Why did you choose this direction of research?
Computer architecture is the foundation of all computer research. Processing-in-memory (PIM) is considered a promising computer architecture solution to enhance the performance of memory-bounded data-intensive applications. With PIM architecture, it is possible to integrate general-purpose or specialized computation units in or near the memory module, thereby reducing the massive data movement, read latency and increasing the bandwidth. PIM is currently a very new research direction, especially for the system community, and there are many open research questions to be answered.
No comments