Understanding Reliability on Shared Edge
- March 21, 2022 by
- Junchen Jiang
Authors: Junchen Jiang, Haryadi Gunawi, Yuyang Huang
What is the central challenge/hypothesis your experiment investigates?
As a new breed of AI applications are widely used in our daily lives, the concept of "shared edge" has grown in popularity as a way for multiple AI applications (each running in a container and on a different data stream) to share network bandwidth and compute resources at the edge services. While shared edge offers new opportunities to run more AI applications together, ensuring that these AI applications return highly accurate inference/prediction results has posed a significant challenge to the conventional paradigm of resource management. This is because today's resource allocation systems, designed to optimize traditional notions of throughput and delay, are unable to directly measure AI application's accuracy. What's exciting about this direction is that new frameworks for resource sharing and management are needed.
In this project, we specifically study video-analytics applications, whose emergence has created challenges for resource management in edge environments, because (1) traditionally resource managers don't directly observe accuracy, and (2) modern video analytics applications are highly adaptive, so observing throughput and latency doesn't always reveal changes of accuracy.
How is your research addressing this challenge?
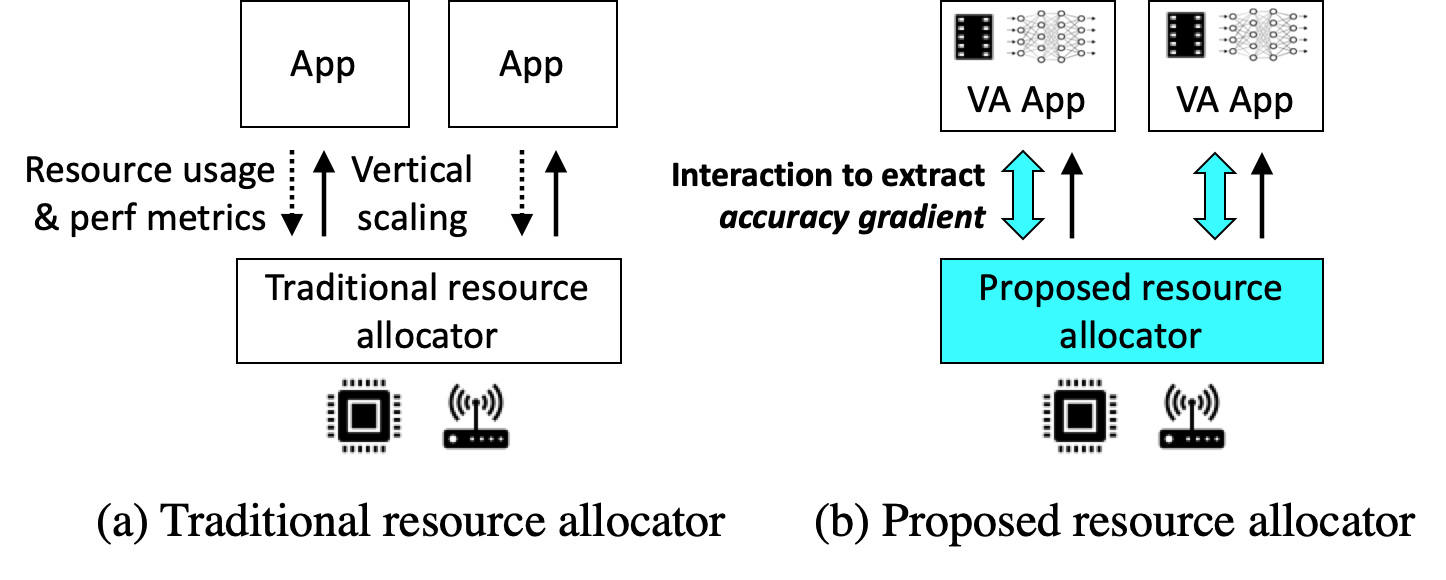
Our project proposes a new resource-management primitive of dynamically monitoring how much each application's accuracy might change with more or less resources. This primitive enables the resource manager to allocate compute/network resources to applications that are most in need of them. To do so, we create a simple-yet-efficient interaction between the resource manager and the video-analytics applications. As illustrated in this figure, each video analytics application (VAP) shares the gradient with respect to the amount of allocated resource changes of its output between two different resource allocations, and then the edge resource manager (left) uses the information to allocate resources among the applications in a way that maximizes the overall improvement of inference.
How do you structure your experiment on Chameleon?
A typical setup of our experiment consists of one GPU server from the CHI@UC site and one or multiple containers running on CHI@Edge’s Raspberry PI 4 devices, where they are communicating using the Chameleon’s Floating IP. To run the experiment, we first reserve and configure the environments (OS, container, Floating IP, etc.) for the GPU server or edge devices through Chameleon’s GUI. We then modify or start the experiments by SSH-ing onto the corresponding server or containers. In addition, we often use the system snapshot capability (i.e. cc-snapshot) as it can save so much time on configuring the environments (dataset, CUDA, python, etc.) when we need to resume the experiment on a new server.
When we first started using Chameleon, we found the documentation to be particularly detailed and helpful in guiding us through the process like reserving bare-metal servers, starting the servers, or exposing the server with Chameleon’s Float IP. Thus, we recommend anyone who wishes to start experimenting on the Chameleon to follow the documentation and the examples in it because this could help them understand the structure and logistic of the Chameleon testbed. We also found that the Chameleon team has been very helpful and responsive to our questions.
What features of the testbed do you need in order to implement your experiment?
Since the project is still in its early stage, we have kept the experiment setting as simple and straightforward as possible and have not explored some of Chameleon’s advanced features, such as custom kernel boot or network stitching. However, one feature did play a critical role in our current experiment setting: the bare-metal access to GPU machines with configurable network connections with edge devices. If Chameleon was not available, implementing our experiment would require purchasing a standalone GPU server shared by several projects, and our experiment and the results would be affected by the resource availability of such a server. The bare-metal access to a powerful GPU server on Chameleon significantly reduces the cost of equipment purchasement and hardware maintenance for our experiment.
Can you point us to artifacts connected with your experiment that would be of interest to our readership?
We plan to open source the codebase, including the implementation and experiment codes based on Chameleon and CHI@Edge, on a public code repository once they are ready: https://github.com/ShadowFient/VAP-Concierge

Image courtesy of the author
About the author:
Junchen Jiang is an Assistant Professor of Computer Science at the University of Chicago. He received his PhD degree from Carnegie Mellon University in 2017 and his bachelor's degree from Tsinghua University in 2011. His research interests are networked systems and their intersections with machine learning. He is a recipient of Google Faculty Research Award in 2019, Best Paper Award at the Symposium of Edge Computing in 2020, and CMU School of Computer Science Doctoral Dissertation Award in 2017.
How do you stay motivated through a long research project?
As a student, my biggest drive to do research was the feeling that I'm the first to see something no one has seen before. Even if it's a trap ahead and I fall into it, that's still worth it. It was just that simple!
As a faculty, though this may sound surprising, the greatest drive for me has always been the passion of my students. It's true that I sometimes motivate students, but once they are warmed up with a project, I'm constantly fascinated by how students lead a project to new directions, and I've always enjoyed being "pushed" by students to bounce off ideas with them, give feedback, and work closely with them before the deadline.
No comments