Pegasus at the Edge
- Dec. 20, 2021 by
- Ryan Tanaka
On the current research:
The proliferation of IoT devices being used in various fields from environmental monitoring, transportation, and surveillance has necessitated the development of tools which support distributed computing on devices with limited resources at the edge. Pegasus [1] , a fully featured workflow management system (WMS), was developed to enable scientists in a wide variety of domains including astronomy, seismology, and physics to easily develop, run, monitor, and debug their scientific workflows on a diverse range of computing platforms such as grids, clouds, and HPC systems. Built upon the tried and tested execution engine provided by the HTCondor [2] software suite, Pegasus, jobs can run essentially anywhere that an HTCondor worker can be spawned and reached via the network. As such, in this talk we explore running Pegasus jobs on the IoT devices made available through the CHI@Edge testbed.
On addressing the research challenge:
Drawing inspiration from two systems: GlideinWMS [3] and Pyglidein [4], we will explore a use case where HTCondor workers are to be spawned on heterogeneous devices, on demand, based on the volume of jobs enqueued and available compute resources at any given time. Using our experience gained in this effort, which we call Pegasus@Edge, we aim to provide the workflow community with a containerized solution to running Pegasus jobs on ARM edge devices. When doing these runs, we wanted to start up HTCondor workers on CHI@Edge devices without occupying project resources for extended periods of time to allow for other users to access these devices. To accomplish this, we have a tool that periodically computes a load value based on jobs queued and idle compute resources, and provisions more workers when that load value exceeds a given threshold. The following figure illustrates this on demand provisioning.
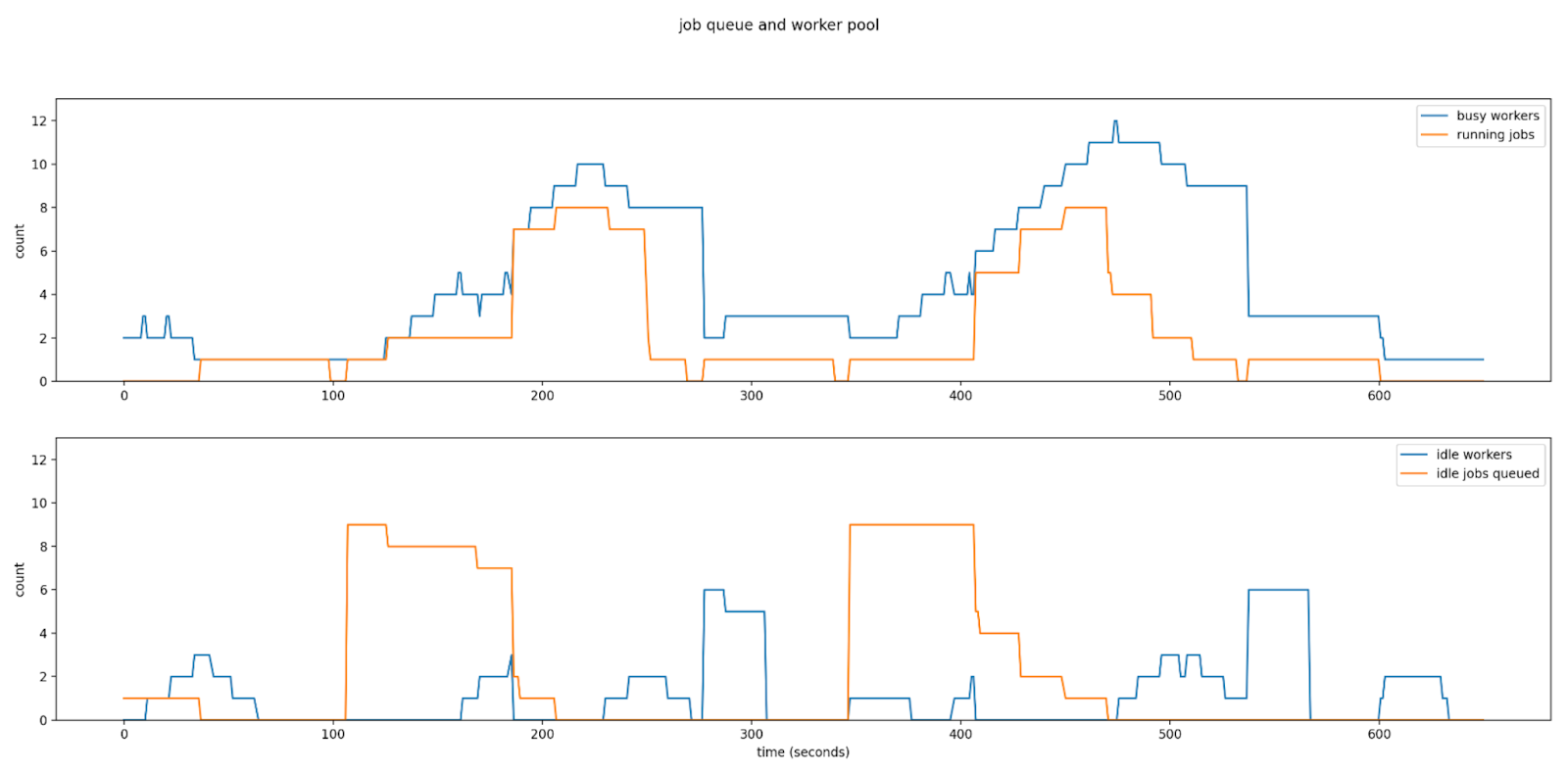
IoT devices are typically small, low powered, single board computers with limited CPU cores, random access memory, and persistent storage. To utilize such devices effectively for edge computing involves understanding both your workload and the underlying hardware limitations of the device on which it will run. As part of our FlyNet [5] project, which aims to provide an architecture and toolset that will enable scientists to incorporate edge computing devices in their computational workflows, we investigated the performance of the ffmpeg [6] video tool on the Raspberry Pi 4. In this second part of our talk, we will share performance benchmarks obtained using pegasus-kickstart [7], a wrapper program developed to monitor job execution, of the ffmpeg software running on the Raspberry Pi 4 when serving as both the role of a video streaming server and as a client. Based on these preliminary benchmarks, we draw attention to the hardware bottlenecks of the Raspberry Pi 4 and discuss ways in which these may be circumvented.
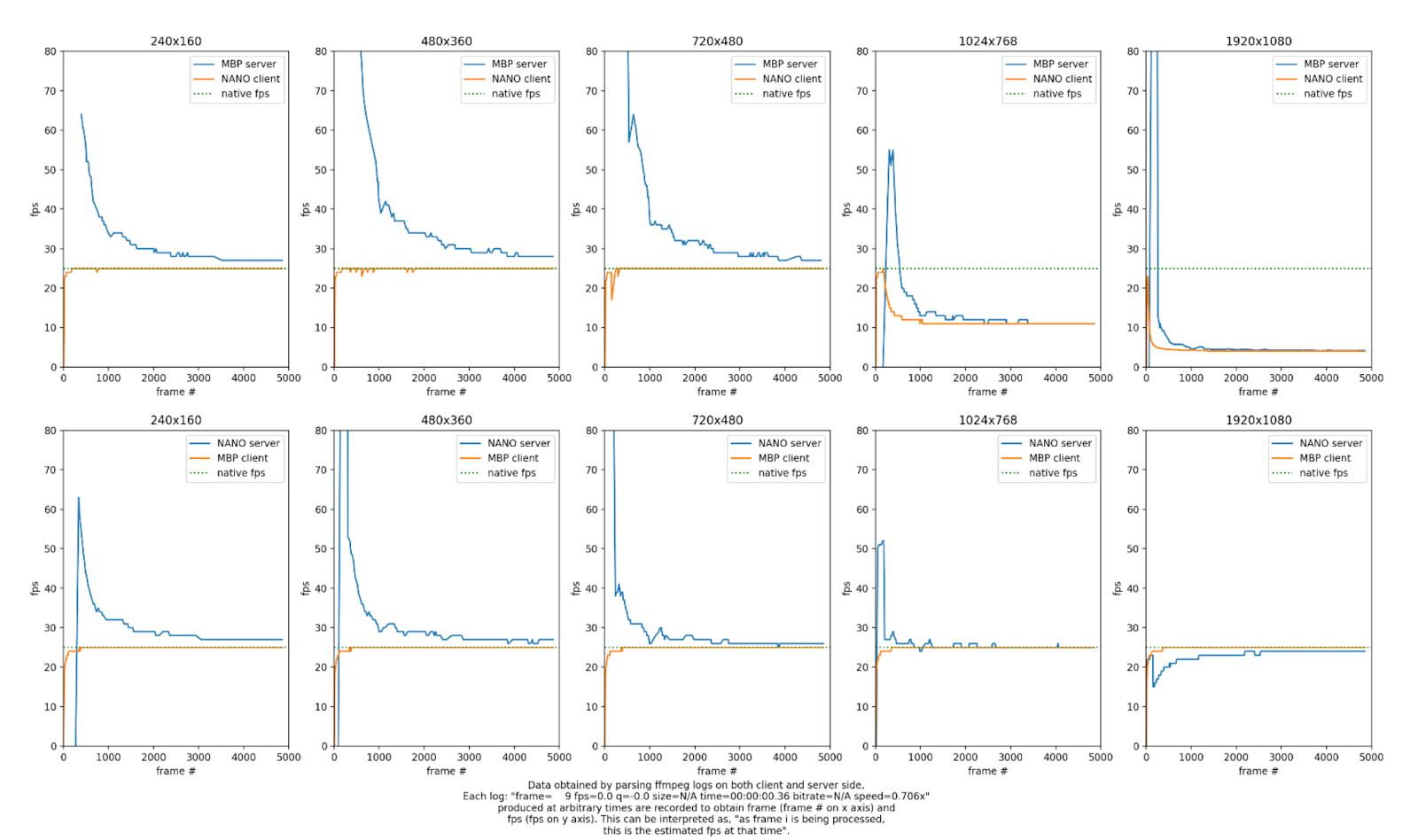
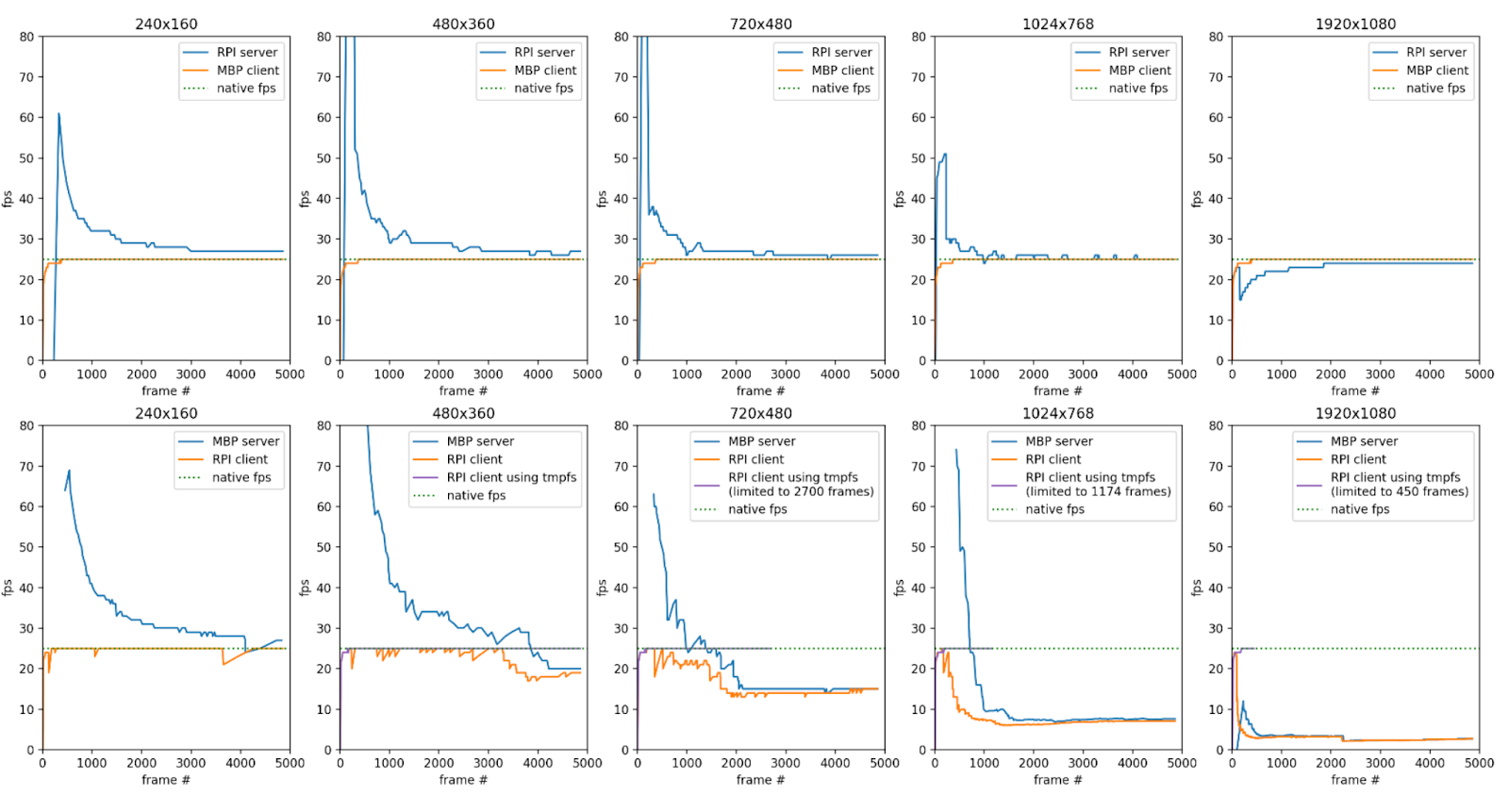
The figures above illustrate FPS reported from ffmpeg when serving and receiving videos of various resolutions. At higher resolutions, Raspberry Pis and Jetson Nanos equipped with SD cards do not have the write speed necessary to save individual frames at near real time, a potential bottleneck for applications doing video analytics. This bottleneck is further illustrated in the following plot where we illustrate the time it takes for Jetson Nano and Raspberry Pi devices to receive and save individual frames of a 194 second video. One solution to overcome this is to write frames to tmpfs, assuming that they can fit in memory. This is illustrated by the purple line in the plot above where the ffmpeg client’s reported FPS remains the same as the native FPS of the video.
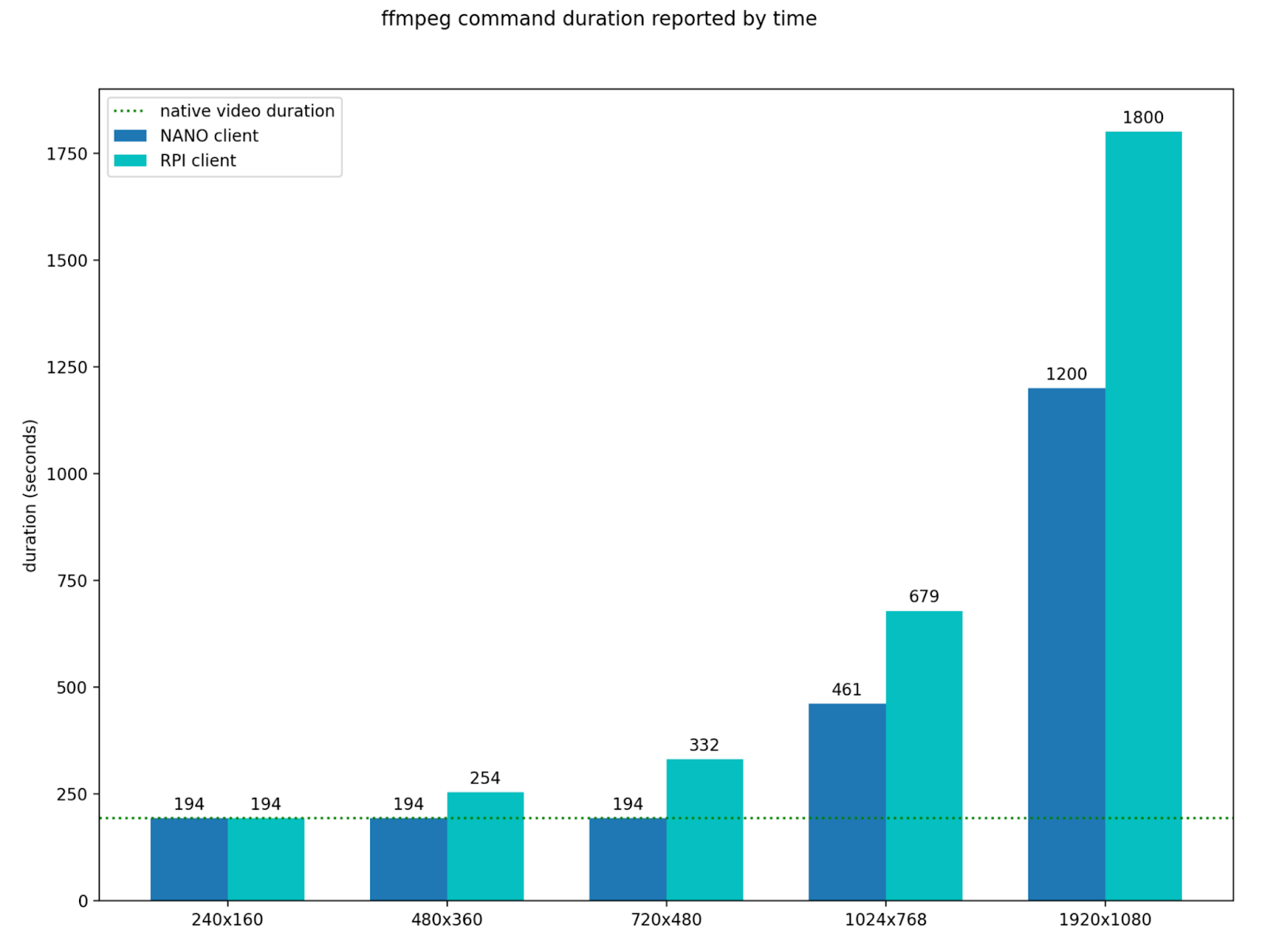
On their most powerful piece of advice:
This testbed is great because I didn’t have to set up any IoT devices for myself. Additionally, Chameleon has provided a good initial set of devices to try out. While doing experiment runs, we did encounter several issues where containers were unable to be started on devices for which we had already received a reservation. These hiccups were infrequent, and the CHI@Edge developers were quick to resolve any issues.
Despite still being in preview, the CHI@Edge testbed has added great value to our work. The Jupyter notebooks provided during the CHI@Edge webinars were a great starting point, and using those, we were able to get our experiments up and running quickly. Also, we have greatly benefited from not having to manage our own edge infrastructure and, moving forward, it will be easy for us to test workflow experiments that incorporate both core cloud resources and edge devices.
With future experiments in mind, bare-metal reconfiguration and network stitching are the two of the most attractive features to us.
About the author:

My name is Ryan Tanaka and I am a Research Programmer at the USC Information Sciences Institute in the Science Automation Technologies group. I joined ISI after completing my masters in computer science at the University of Hawaii at Manoa in 2019. My work is focused on distributed systems and I am currently working on developing features for the Pegasus Workflow Management System. In my free time, I enjoy running.
On his most powerful piece of advice:
Find great mentorship, and be a great mentor to others when you have the chance.
On staying motivated throughout a research project:
-
Have a roadmap planned out of what you want to accomplish and how you intend to do so.
-
Set small, achievable goals.
Interested readers can explore the following resources for more information:
Presentation about this research at the September 2021 CHI@Edge Workshop: Recording on YouTube
References:
[1] E. Deelman, K. Vahi, G. Juve, M. Rynge, S. Callaghan, P. J. Maechling, R. Mayani, W. Chen, R. Ferreira da Silva, M. Livny, and K. Wenger, “Pegasus: a Workflow Management System for Science Automation,” Future Generation Computer Systems, vol. 46, p. 17–35, 2015., (Funding Acknowledgements: NSF ACI SDCI 0722019, NSF ACI SI2-SSI 1148515 and NSF OCI-1053575)
[2] D. Thain, T. Tannenbaum, M. Livny, Distributed computing in practice: The condor experience, Concurrency and Computation: Practice and Experience 17 (2-4) (2005) 323–356. doi:10.1002/cpe.v17:2/4.
[3] W Andrews, B Bockelman, D Bradley, J Dost, D Evans, I Fisk, J Frey, B Holzman, M Livny, T Martin, A McCrea, A Melo, S Metson, H Pi, I Sfiligoi, P Sheldon, T Tannenbaum, A Tiradani, F Würthwein and D Weitzel, "Early experience on using glideinWMS in the cloud", Journal of Physics: Conference Series, Vol. 331, No. 6, 2011
[4] D Schultz, B Riedel, & G Merino (2017). Pyglidein - A Simple HTCondor Glidein Service. Journal of Physics: Conference Series, 898, 092018.
[5] http://www.ecs.umass.edu/flynet/
[6] http://ffmpeg.org/
[7] G. Juve, B. Tovar, R. Ferreira da Silva, D. Krol, D. Thain, E. Deelman,W. Allcock, and M. Livny, “Practical resource monitoring for robust high throughput computing,” in Workshop on Monitoring and Analysis for High Performance Computing Systems Plus Applications, 2015.
No comments