New Experiments with New CHI@UC Hardware
- Oct. 25, 2021 by
- Michael Sherman



'The story so far: in the beginning, the universe was created. This has made a lot of people very angry and been widely regarded as a bad move'. To make it a bit better, though after a long delay caused by a series of unforeseen events which in the end were a direct result of the aforementioned bad move, we are now releasing Chameleon Phase 3 hardware. Learn more about the different types of hardware and what kind of experiments they're best suited for!
The hardware includes:
- 42x Intel nodes with 48 cores and 192Gb of RAM (compute_cascadelake)
- 10x: AMD Epyc with 48 cores, 256Gb of RAM, and soon to have a zoo of NVME disks. (storage_nvme)
- 2x: Intel Optane nodes with 112 Cores, 768Gb of RAM, and 3TB of NVDIMMs (compute_nvdimm)
- 3x: Intel nodes with 4x Nvidia V100 GPUs connected by NVLink (gpu_v100)
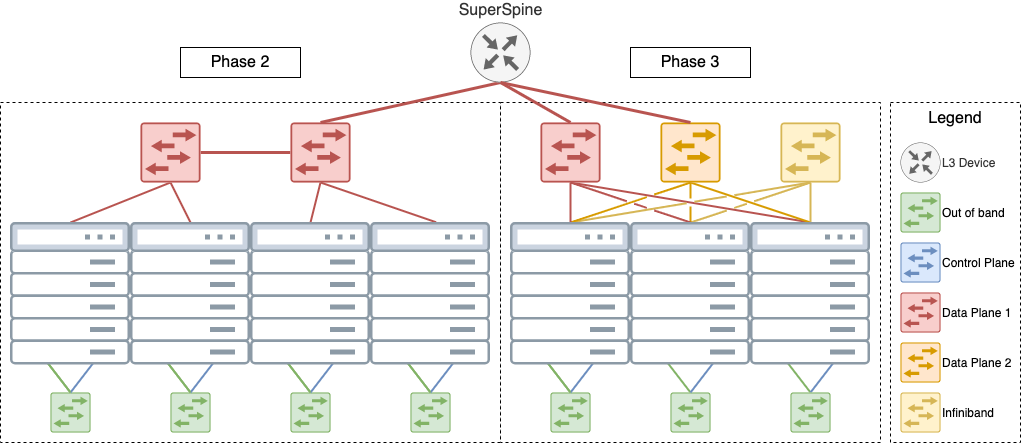
We are also adding 3 new networking dataplanes: All the new nodes are connected by two 25g ethernet connections. In addition, all of the gpu_v100, compute_nvdimm, and 16 of the compute_cascadelake nodes have a HDR100 Infiniband connection, while the storage_nvme have HDR Infiniband to take advantage of PCIe 4.0 for 200Gb/s speeds. Two of the compute_cascadelake nodes will have Xilinx FPGAs added, with more to come.
Now that there are 57 more nodes, we can all breathe a sigh of relief: it should finally be much easier to make a lease. The three gpu_v100 nodes are back, and once supply chains normalize, they’ll be joined by an additional 9 GPU nodes -- though things were taking so long that we may upgrade rather than get the same ones. The storage_nvme nodes are currently “empty”, but we’re planning on adding the following mix of enterprise: Samsung PM1733, Intel D7-P5600, Kioxia CM6-R, SK Hynix PE8010, and consumer: Corsair Force MP600, Samsung 980 PRO, WD SN850, Sabrent Rocket 4 Plus. Please, let us know if these look good to you and/or if you have any other suggestions leave a comment on this blog by the end of the month: we will try to accommodate as many options as we realistically can but time is of the essence.
This hardware was specifically designed to enable experimentation with disaggregated hardware. Since the nvdimm, gpu, and nvme nodes are on the same infiniband network, you can mix and match them to experiment with all sorts of storage and computation strategies. If you just need “regular” nodes with infiniband, we added 16 of the compute_cascade_lake nodes to the same infiniband network.
In addition, this new hardware provides many more networking options and thus opportunities for interesting networking experiments. All of the new nodes have two 25g connections, and a subset have Infiniband, either at 100G or 200G. As seen in the above diagram, all of the Phase 3 nodes are on the same switches, with no bottlenecks between their racks. To make things more usable, all nodes will have a 1g interface connected to Sharednet1 (once the extra cables come in). This means that you will be able to access and control your node via the 1g interface, while reserving the fast interfaces for your experiment traffic. Use a node as a router between other networks, set up traffic sources and sinks, or run a kubernetes cluster with separate control and data planes for NFV experiments.
We’re releasing this hardware as Early Access until the end of the month while we iron out the last of the features. We’ll be updating here as features become available, as well as in the locked cabinet in the basement. Please join us in kicking the tires, and let us know about any other features or hardware that would help your experiments -- and most importantly tell us what is still missing from your perspective, we’d like to put in the order soon. Always trying to make the universe better!
No comments