Profile-Guided Frequency Scaling for Latency-Critical Search Workloads
- June 21, 2021 by
- Vinicius Petrucci



Daniel Araujo-UFBA (left), Denilson Amorim-UFBA (center), Vinicius Petrucci-UFBA/Pitt (right)
The experimental work described here was conducted by Masters student Daniel Araujo in collaboration with the undergraduate student Denilson Amorim, both affiliated with the Universidade Federal da Bahia, from Salvador, Bahia, Brazil. The students were supervised by Vinicius Petrucci (UFBA/Pitt).
On the current research:
Dynamic frequency scaling is a technique to reduce power consumption in computer systems. However, this technique poses challenges when adopted in latency-critical cloud applications, such as web search, because it does not take into account the latency requirements of the running application. Established work on dynamic frequency scaling at OS-level is application agnostic and coarse-granulated in the sense that it considers the entire application process utilization for decision making.
We hypothesize that we can better optimize such latency-critical applications by characterizing and identifying functions/threads that require distinct levels of performance and could then be optimized individually. In that sense, we should be running the CPU at a higher speed only during the activation of a function that requires such a higher performance.
Our experimental work introduces a new approach that combines profiling compute-intensive functions with code instrumentation for thread monitoring and core frequency scaling. Using the Chameleon testbed, we implemented and evaluated our proposal in a real multi-core system. We observed energy consumption savings up to 28% when compared to the recent Linux's Ondemand frequency scaling governor while attaining acceptable levels of performance/latency constraints for a web search application.
On approaching the research challenge:
Our experimental work, called Hurry-Up, proposes a finer-grained dynamic frequency scaling approach for multi-core processors that leverages information about the computational intensity of certain functions in latency-critical search applications. Our solution works by identifying that individual requests can demand distinct CPU processing time, thus the frequency can be adjusted to match the request's demand. The idea is to dynamically track the execution stage of the most compute-intensive threads and to adjust the associated CPU frequency based on the stage information. The execution stage is characterized by two information sources: (1) whether or not the thread is executing a particular “hot function”, and (2) for how long it has been running in the “hot function”.
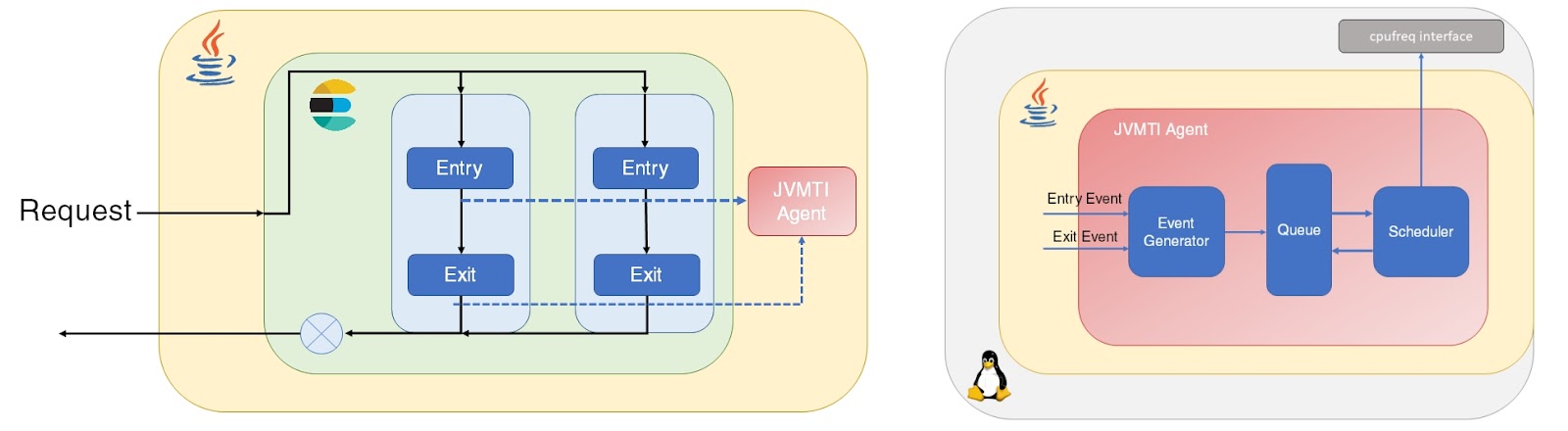
At a high level, as shown in the figure below, every thread entry and exit event on a hot function is intercepted at run-time by the Java Virtual Machine Tool Interface (JVMTI) agent (shown on the left). In the JVMTI agent, shown on the right-hand side figure, there is an Event Generator, which pushes the entry and exit events to the Event Queue; the Frequency Scheduler consumes the events from this queue and performs the CPU frequency changes using the cpufreq Linux interface.
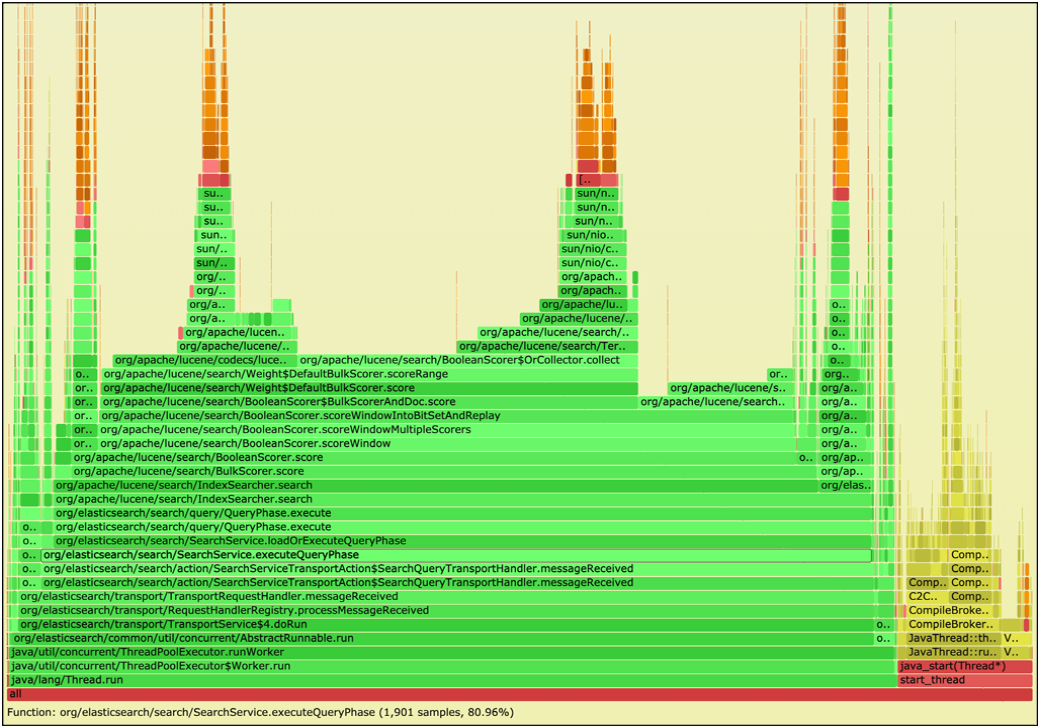
We deployed Elasticsearch as our latency-critical benchmark. We identified Elasticsearch's hot function while running the benchmark with previous representative input traces. We generated a Flame Graph of Elasticsearch (see figure below) after running it using the Linux perf tool. We found that the method “org/elasticsearch/search/SearchService. executeQueryPhase” dominated about 81% of the search process. We selected this particular method as our “hot function” from the call stack since it is the top function in the stack from the search Java package.
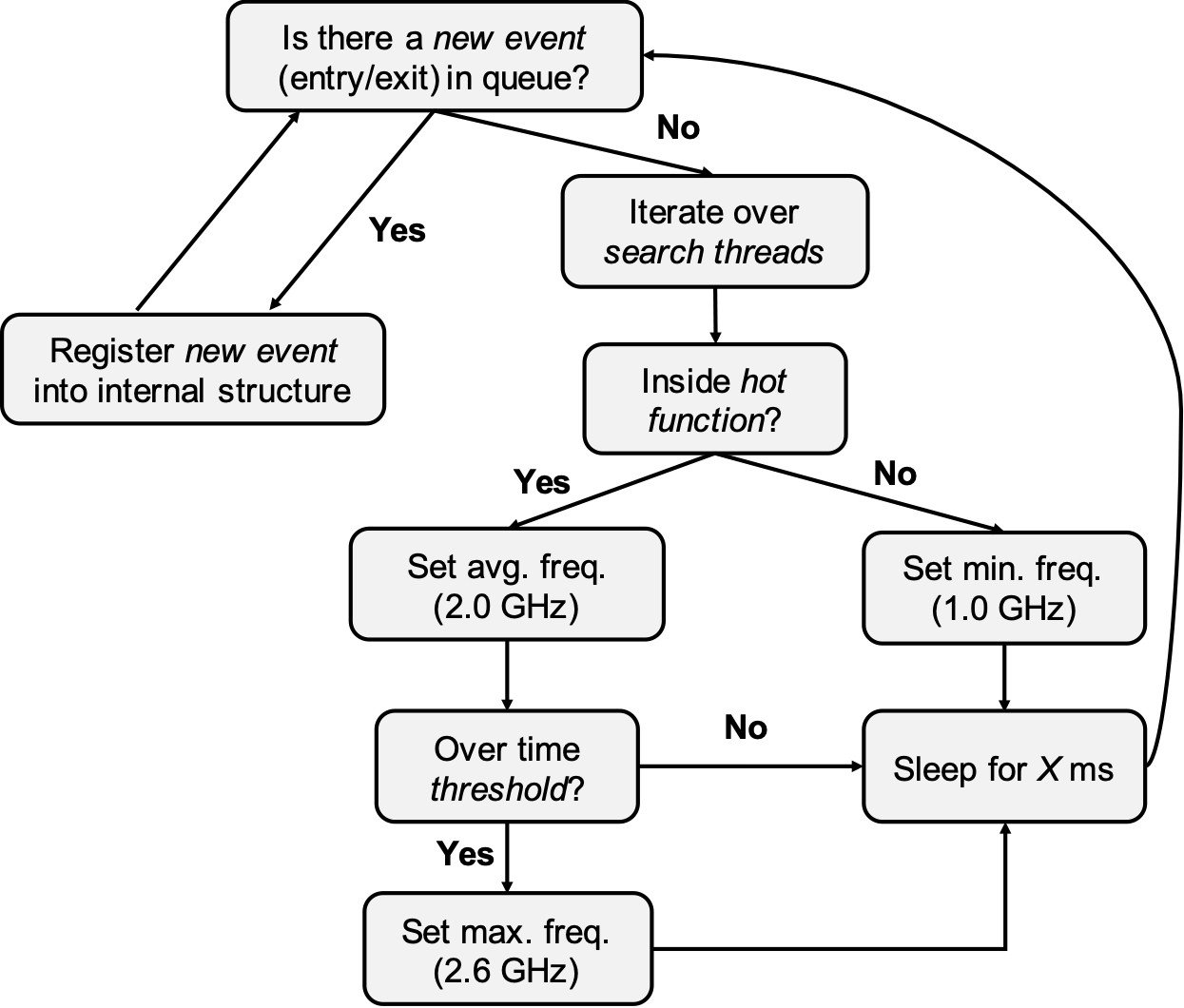
During the search process, our frequency scaling solution works by reacting to hot function entry/exit events that are intercepted at run-time. A flowchart of the frequency scheduler logic is shown below. Recall that every thread entry/exit to/from the hot function generates an event that is pushed into the Event Queue that is consumed by the scheduler. Based on those events, the Scheduler is responsible for increasing or decreasing the CPU frequency running each thread based on the executing stage of these search threads. Each event has information about what core each thread is running at, a timestamp for detecting if this thread is over a particular time threshold, and status (e.g. either an entry or leave event).
On testbed needs:
The key feature from Chameleon was the access of bare-metal instances with root access to be able to control the voltage/frequency of individual CPU cores and to measure the CPU power consumption using Intel’s RAPL interface. In particular, this feature allowed us to choose our desired processor architecture (we used both Intel’s Skylake and Haswell, as they both had per-core dynamic frequency support) and also our OS-flavor, while letting us customize it. During the course of the research, we had to change the default kernel’s boot configuration (using ACPI energy driver instead of Intel’s pstate, for example) and even the kernel itself - and Chameleon did allow us to do it. We also used Chameleon’s infrastructure for packing our modified OS into a snapshot, storing it in the cloud, and starting multiple instances with it. All we can say is that this kind of research would be a lot harder without Chameleon’s infrastructure. We are very thankful for this support!
About the author:
I am an Assistant (tenured) Professor (on leave) at UFBA, Brazil, and Assistant Teaching Professor at the University of Pittsburgh, USA.
My primary research interests concentrate on computer systems with an emphasis on improving resource efficiency while delivering real-time performance guarantees. I have focused on understanding the tradeoffs of energy (e.g. save energy by running a bit slower) and performance (e.g. need to meet user expectations, always!) and exploring this knowledge to design better dynamic resource management approaches.
Check out my Google Scholar for up-to-date publications and citations.
On his most powerful piece of advice:
I believe an important step is to acknowledge that research is hard as you are required to pursue both high-quality work and novelty. If students are told that research is an easy and natural process, and in fact, they find that it is hard, which is, they won’t think "Oh! That was a lie", they will think "I'm not good at research and should quit."
My piece of advice is that students should not pay attention to thoughts like "I am not good enough to do research" or "I am dumb since I am struggling with my research". It is OK being “stuck” and sometimes not making any (visible) progress. Actually, in the long run, you just need to be comfortable with a certain level of ambiguity and uncertainty, and to be good at being "stuck" now and then. Research is a long-term process, and you should just keep it up, continue putting great effort into your work, and naturally, good stuff will come out from all this process.
Especially for new graduate students, I recommend watching “Graduate School: Keys To Success'' (link) by Remzi Arpaci-Dusseau (Wisconsin). It was very inspiring to me!
From this presentation, I found the following quote impactful: “It’s hard to make something that’s interesting… Basically, anything that anyone makes… It’s like a law of nature, a law of aerodynamics, that anything that’s written or anything that’s created wants to be mediocre. It’s all tending toward mediocrity the way that all the atoms are dissipating out toward the expanse of the universe. Everything wants to be mediocre, so what it takes to make anything that is more than mediocre is an extreme act of will. You just have to exert so much will into something for it to be good.” - Ira Glass (This American Life)
Additional reading:
This research work was accepted to be presented and appear at the IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGRID) on May 10-13, 2021. You can find a copy of the paper here.
The source code of our solution with instructions for reproducibility is open and available at https://github.com/raijenki/elastic-hurryup/
No comments