High-Performance Federated Learning Systems
- May 17, 2021 by
- Zheng Chai
This work is part of George Mason University PhD student Zheng Chai and Prof. Yue Cheng’s research on solving federated learning (FL) bottlenecks for edge devices. Learn more about the authors, their research, and their novel FL training system, FedAT which already has impressive results, improving prediction performance by up to 21.09% and reducing communication cost by up to 8.5 times compared to state-of-the-art FL systems.
On the current research:
Our research is focused on solving traditional bottlenecks of Federated Learning (FL), FL is a machine learning technique that learns a shared model across decentralized edge devices without exchanging local devices data. First, a little background about FL. In a typical FL framework, a shared model is learned from a large number of distributed clients with the coordination of a centralized server. Different clients in a FL deployment do not share the training dataset with each other due to security and privacy reasons. Instead, each client trains a local model using its local data; the server aggregates the learned gradients of all local models in order to train a global model. Google keyboard next-word prediction (Hard et al. and Yang et al.) is a typical application of FL.
This form of collaborative learning exposes new challenges as well as new tradeoffs among model convergence speed, model accuracy, balance across clients, and communication cost. Some challenges include:
(1) straggler problem---Clients have training time (including transmission time) heterogeneity due to data or (computing and network) resource heterogeneity. In synchronous FL systems, the training time of one round depends on the training time of the slowest client. stragglers could slow down the training process and reduce the overall performance.
(2) communication bottleneck---where a large number of clients communicate their local updates to a central server and bottleneck the server.
Many existing FL methods focus on optimizing along a single dimension of the tradeoff space (e.g., Xie et al.; Chen et al.; Jeong et al.; Mills et al. ). Existing solutions use asynchronous model updating or tiering-based, synchronous mechanisms to tackle the straggler problem. However, asynchronous methods can easily create a communication bottleneck, while tiering the clients into different tiers may introduce biases that favor faster tiers with shorter response latencies.
On approaching the research challenge:
To address these issues, we present FedAT, a novel FL training system with asynchronous tiers under Non-i.i.d. training data, Non-i.i.d. denotes Independent and Identically Distributed and means different data distribution among clients. FedAT synergistically combines synchronous, intra-tier training and asynchronous, cross-tier training. By bridging the synchronous and asynchronous training through tiering, FedAT minimizes the straggler effect with improved convergence speed and test accuracy. FedAT uses a straggler-aware, weighted aggregation heuristic to steer and balance the training across clients for further accuracy improvement. FedAT compresses uplink and downlink communications using an efficient, polyline-encoding-based compression algorithm, which minimizes the communication cost. Results show that FedAT improves the prediction performance by up to 21.09% and reduces the communication cost by up to 8.5 times, compared to state-of-the-art federated learning methods.
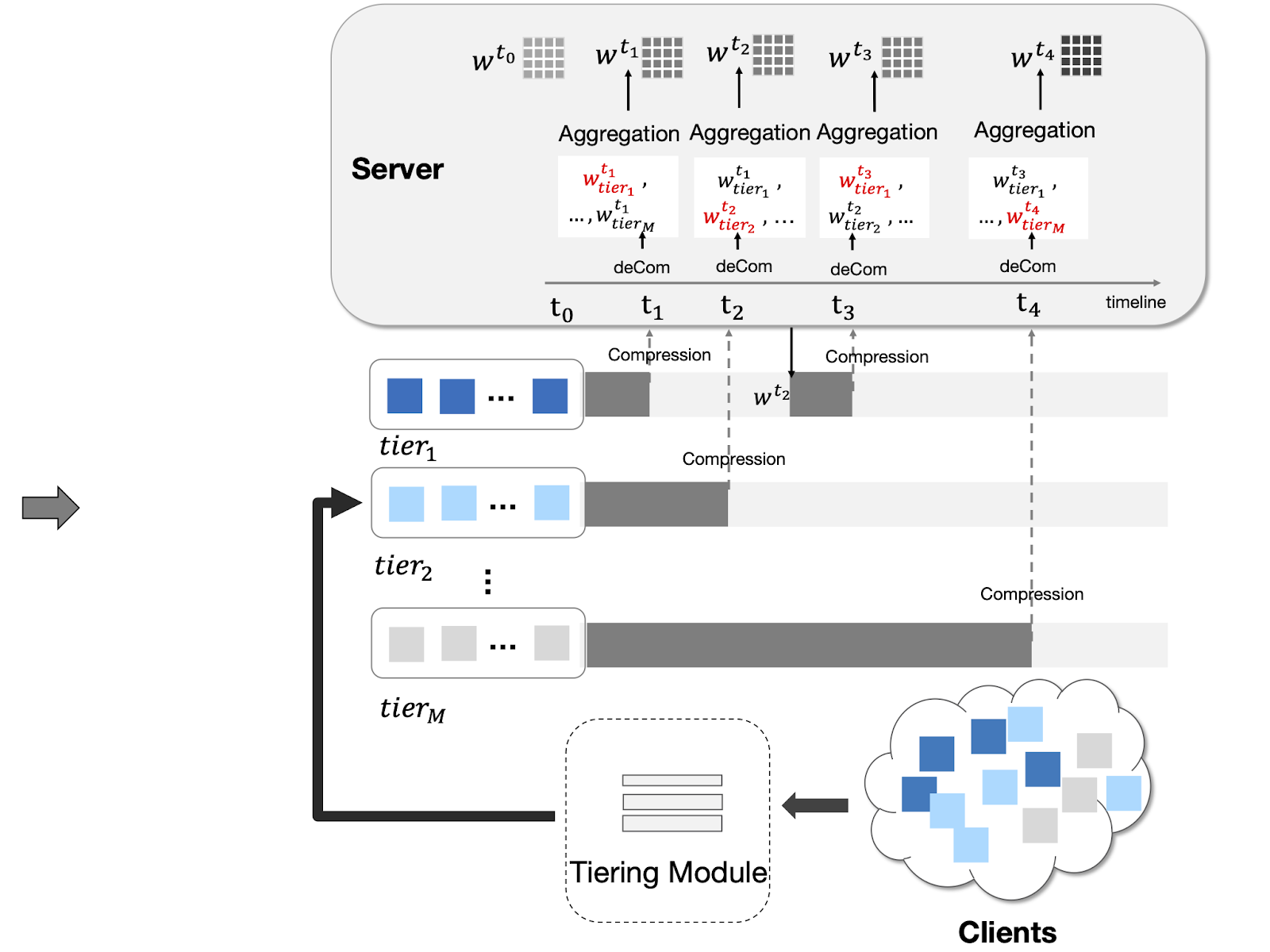
The figure above shows the training process of FedAT. The tiering module profiles and partitions involved clients into M tiers based on their response latencies. The server maintains a list of M models, one for each tier, reflecting the most updated view of per-tier local models, at a certain round t. Correspondingly, the server also maintains a global model w that gets asynchronously updated from M tiers. Each tier performs synchronous update process, a fraction of clients are selected randomly and compute the gradient of the loss on their local data, then send the compressed weights to the server for a synchronous update to the tier model on the server.
FedAT expands on our existing work called TiFL [HPDC’20], which is a synchronous, tiered FL system that adaptively classifies clients into different tiers based on performance and training quality.
On testbed needs:
Chameleon’s bare-metal feature is unique for us. Since communication efficiency is one of the advantages proposed by our model, the network traffic between the server and clients is a valuable evaluation metric when comparing our approach with other state-of-the-art FL methods. This feature allows us to record the traffic precisely. In addition, Chameleon’s bare-metal servers are equipped with powerful computing and memory resources; this enables us to conduct medium- and large-scale FL simulation studies that target a diversified range of hardware configurations for a large number of training clients.
On encountering obstacles that stand in the way of FL experimentation:
Due to the lack of a real-world FL testbed, current FL research work and research prototypes are evaluated on small- to medium-scale testbed clusters using simulated FL clients. While a simulated experimental deployment provides a well-controlled environment for verification and validation purposes, it is often difficult for simulated testbeds to faithfully capture all the workload assumptions that may exist in a real-world FL deployment. It would be desirable to have access to large-scale testbeds with real-world edge devices such as microservers and smartphones, for systems research such as FL systems optimizations and redesign.


Images of Zheng Chai and Prof. Yue Cheng, courtesy of the authors
About the authors:
Zheng Chai (https://zheng-chai.github.io/) is a third-year Ph.D. student of Computer Science at George Mason University. He is currently working with Prof. Yue Cheng on distributed systems and machine learning. His major research interests include distributed machine learning system, federated learning system, high-performance computing, and storage system. His research aims at: 1) building high-performance systems for large-scale machine learning, and 2) using machine learning technology to improve computer systems. He hopes to continue his research in systems and machine learning after graduating with a Ph.D. degree. In his free time, he loves running and traveling.
Yue Cheng (https://cs.gmu.edu/~yuecheng/) is an assistant professor of Computer Science at George Mason University. He received his Ph.D. in CS from Virginia Tech in 2017. His research interests include distributed and storage systems, cloud and serverless computing, high-performance computing, and machine learning systems. He is a recipient of several highly-competitive awards and honors such as NSF CAREER Award (2021) and Amazon Research Award (2020). His research has appeared at top conferences such as EuroSys, ATC, FAST, and SC. He has served on the Program Committee of a series of top venues including SC’20 and HPDC’18-21.
On their most powerful piece of advice:
By reading we enrich the mind; by conversation we polish it.
Additional reading:
Our latest paper is currently under review. Interested readers can find an arXiv version of the FedAT work at: https://arxiv.org/abs/2010.05958. The corresponding software artifact will be open source for public use when our paper gets published.
No comments