Biometric Research in The Cloud
- Jan. 20, 2021 by
- Keivan Bahmani
January’s User Experiment’s blog features Keivan Bahmani, a PhD candidate at Clarkson University. Learn more about Bahmani and his use of Chameleon for biometric research.
On his background: I remember as a child, I was fascinated by computers and computer networks. Predictably, I got my bachelor of science in Electrical Engineering back in my home country (Iran). Afterward, I moved to Cyprus to continue my education and get my M.S. During my time in Cyprus, I was teaching C++ programming and Computer networking to undergraduate students. Finally, in 2016 I moved to Potsdam, NY to get my Ph.D. in Electrical and Computer Engineering.

Figure 1: Teaching high school students about biometrics
On research and personal interests: Currently, I am working under the supervision of Dr. Stephanie Schuckers. My work is mainly focused on pattern recognition and machine learning in Biometrics. More specifically, my current research is on deep learning-based liveness detection in face and fingerprint recognition systems. In my free time, I enjoy playing electric guitar and cooking.
On his current research and using Chameleon:
|
|
|
|
Figure 2: Fingerprint Spoofs |
Figure 3: 3D printed mask |


Researchers at the Center for Identification Technology Research (CITeR) have made significant use of Chameleon to support research focused on identification technology and biometric recognition. CITeR is a National Science Foundation (NSF) Industry/University Cooperative Research Center (IUCRC), and advances the state of the art through research defined in tandem with affiliates from government and industry [1].
Biometric recognition systems are designed to provide automatic and reliable identification based on the physiological or behavioral characteristics of a person. Researchers have developed and deployed a biometric pipeline to utilize Chameleon [2] to develop deep learning based biometric models for different tasks. One area of research is the development of presentation attack detection models, designed to distinguish between real and spoof samples (deliberately altered or artificially generated) [3,4] in order to protect biometric systems from spoof attacks. Figures 2 and 3 illustrate spoofs designed to attack fingerprint and face recognition systems.
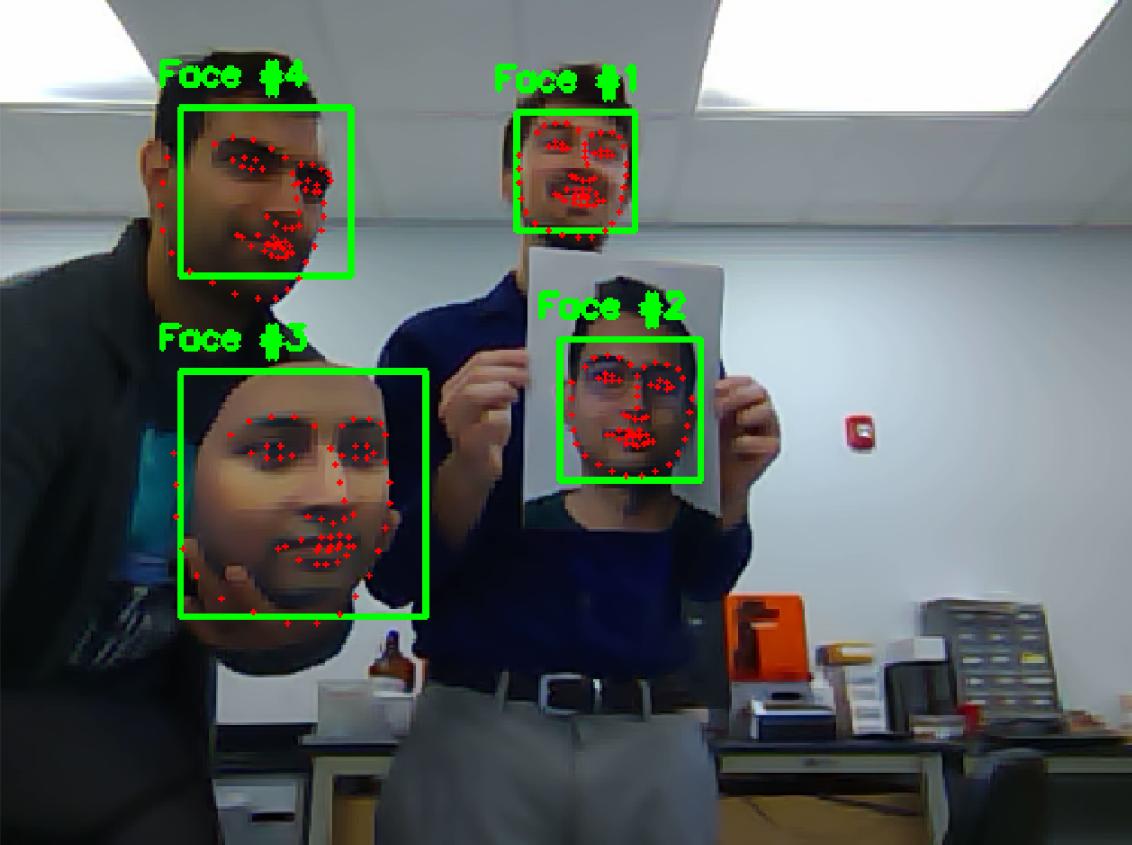
Figure 4: Some spoofs being detected as live samples
Current state-of-the-art biometric models are increasingly relying on deep learning techniques [5]. Developing such models requires a large amount of computational resources. Our biometric pipeline leverages the diverse computational resources provided by Chameleon to effectively develop deep learning based biometric models at scale. Training state-of-the-art deep Convolutional Neural Networks (CNNs) on large datasets is very computationally expensive. This large computation requirement translates into slow model development even in the most powerful GPUs available. Fortunately, Chameleon infrastructure allows us to effectively distribute our model development among many GPU nodes. This drastically speeds up the model development and allows us to run experiments that are simply not possible in single GPU nodes in a reasonable time frame. Our biometric pipeline leverages the Neural Network Intelligence (NNI) platform developed at Microsoft [6]. NNI allows us to distribute our model development among many GPU nodes with very low overhead. NNI works in conjunction with modern deep learning libraries such as Tensorflow or PyTorch [7,8] to effectively scale our deep learning model development process across multiple CPU/GPU nodes at Chameleon. We believe this combination provides a unique balance of ease of use and performance that could potentially be attractive to deep learning practitioners/researchers on Chameleon.
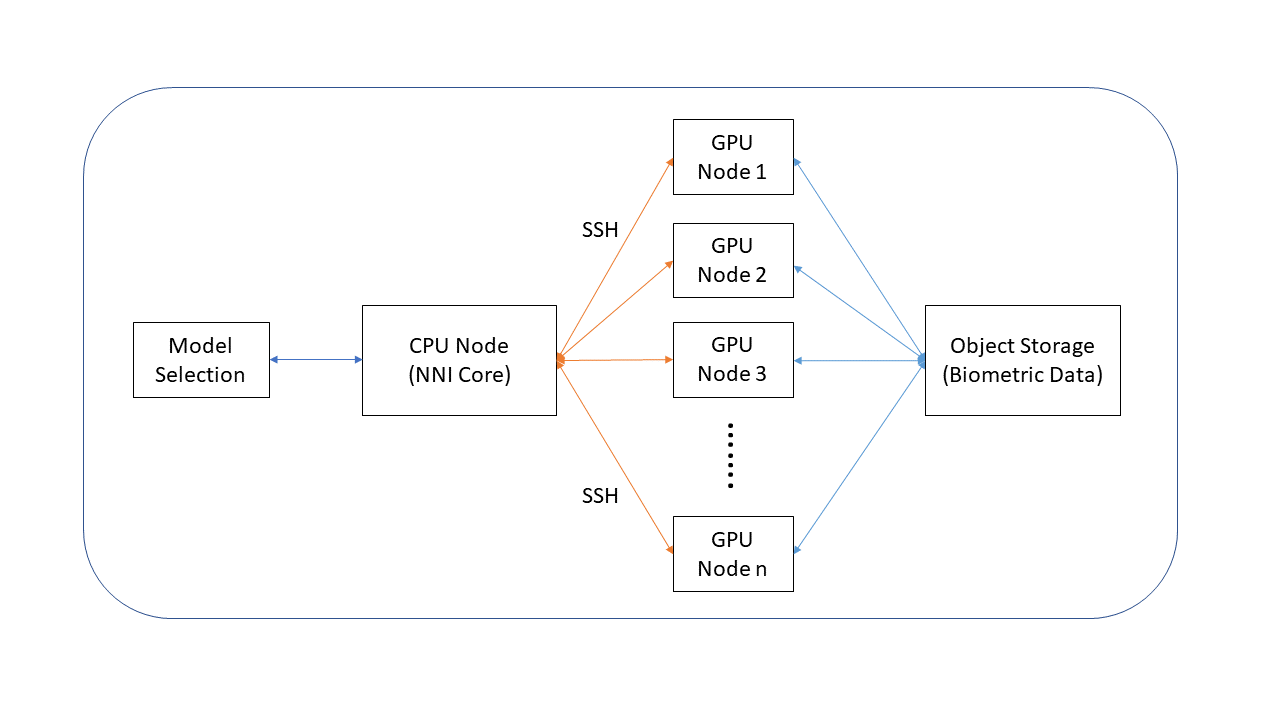
Figure 5: Outline of our biometric pipeline.
Figure 5 presents the outline of our biometric pipeline. We utilize the persistent memory (Object storage) provided by Chameleon to store the biometric samples (face and fingerprint images). Chameleon’s persistent storage handles the transfer of large datasets required for training deep models. The rest of the necessary communication between the nodes involves model parameters and performance metrics. These updates are much smaller in size and can be easily carried over the network connections between the nodes.
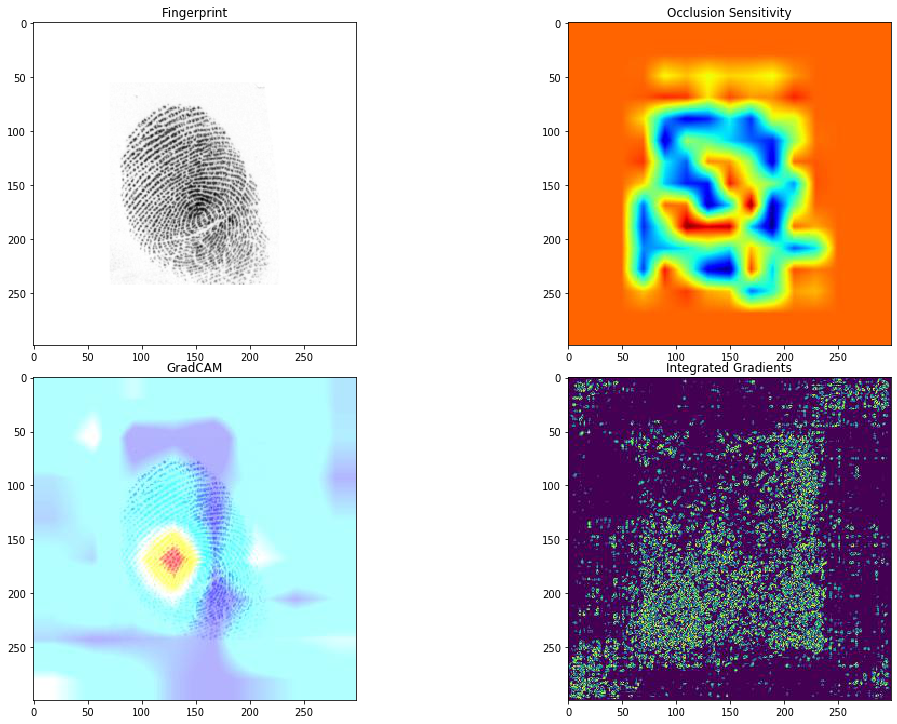
Figure 6: Interpretability models developed on top of Chameleon.
This setup is relatively easy to configure and allows the user to easily scale the experiment to the available Chameleon nodes. For our biometric experiments, we usually utilize a CPU node as an NNI Core and several GPU nodes for training. Through this pipeline, we can simultaneously run several training experiments, compare the results, and update our model selection parameters over multiple nodes. NNI provides state-of-the-art algorithms as well as a very rich and user-friendly API for this task. Additionally, the computational capabilities provided by Chameleon allow us to leverage various explainable models and try to explain and interpret the decisions made by our biometric models [9]. Figure 6 depicts an example of the interpretability models developed on Chameleon for our deep learning-based fingerprint age estimation model. These explainable models can allow us to answer what parts of the fingerprint image are being used to estimate the age of the subject.
On obstacles that stand in the way of biometric experiments: The limiting factor in many of our experiments is the availability of datasets. Our work involves collecting and analyzing biometric samples from human subjects. Due to privacy concerns, such datasets are not publicly available to researchers. This drastically limits the experiment we can run and sometimes makes it impossible to replicate previous work.
On why he chose to pursue research: I like creating new things. It gives me pleasure to build a new system from the ground up and see people use it and enjoy it in their life.
On researchers he admires:
Dr. Carl Sagen for his incredible ability to put complex topics in simple words.
Dr. Richard Dawkins for helping us understand life and for the Richard Dawkins foundation for reason and science.
On his most powerful piece of advice for students beginning research: Start with a goal and a clear plan to achieve it. Reevaluate your goal and plan regularly. It is easy to get lost in the noise and lose focus.
For interested readers, the “Clarkson Distributed Neural Search Engine (Clarkson_NNI_R)” Chameleon appliance at TACC center provides an implementation of this pipeline. You can learn more about the author on LinkedIn or visit the CITeR – Center for Identification Technology Research webpage.
References:
[1] https://citer.clarkson.edu/about/
[2] https://chameleoncloud.org/
[3] Plesh, Richard, et al. "Fingerprint Presentation Attack Detection utilizing Time-Series, Color Fingerprint Captures." 2019 International Conference on Biometrics (ICB). IEEE, 2019.
[5] Sundararajan, K., & Woodard, D. L. (2018). Deep learning for biometrics: A survey. ACM Computing Surveys (CSUR), 51(3), 1-34.
[6] https://github.com/Microsoft/nni
[7] https://github.com/tensorflow/tensorflow
[8] https://github.com/pytorch/pytorch
[9] Samek, Wojciech, et al., eds. Explainable AI: interpreting, explaining and visualizing deep learning. Vol. 11700. Springer Nature, 2019.
No comments