Chameleon and Reproducibility: LinnOS Case Study
- Oct. 31, 2020 by
- Levent Toksoz
Authors: Levent Toksoz and Mingzhe Hao
LinnOS is one of the first that utilizes machine learning inside the OS to infer I/O speed for flash storage at per-I/O granularity in real-time and helps parallel storage applications achieve performance predictability. It supports black-box SSD devices and real production traces without requiring any extra input from users. In addition, it outperforms industrial mechanisms and other approaches. More specifically compared to hedging and heuristic based methods, it improves the average I/O latencies around 9.6% to 79.6% with a reasonable per I/O overhead of 4-6?s.
We used Chameleon’s Jupyter interface to implement our experiments since it offers cell level execution with strong support for documentation to create easy to understand and execute “presentation” projects. Chameleon’s Jupyter interface also allows users to book bare metal instances with various complex hardware configurations. This support was very beneficial to our experiment as it requires a storage hierarchy instance with 3 SSDs to successfully execute failover behaviour. Finally, LinnOS utilizes Chameleon’s easy to use publishing system, where users can publish their experiment to Zenodo or Trovi, to be publicly accessible and executable.
We chose to reproduce LinnOS paper, because it provides a wide range of interactions with the Chameleon testbed that covers the entire stack ranging from application-level software to operating system, and hardware (SSD) (such as installing a new Kernel using the Jupyter-Chameleon interface, running Python and Bash scripts on that kernel via the Jupyter-Chameleon interface, etc.).
LinnOS experiment works as follows:
First, we populate the SSD drives with I/O trace sets. Then using those I/O trace sets LinnOS`s lightweight machine learning model is trained and learned weights are saved to the LinnOS Kernel code. Finally the LinnOS Kernel is installed to make real time I/O speed predictions.
We made our packaged experiment available here. The current version of the package only includes comparison between baseline and LinnOS models. Ultimately, we are planning to reproduce most of the experiments shown in the LinnOS paper.
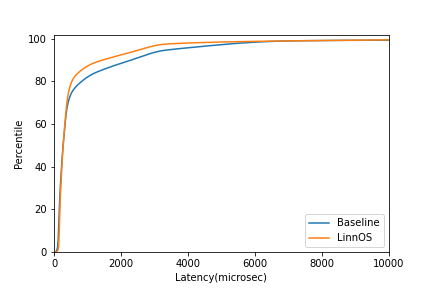
Example graph. Note that when you run the code you don't always get this exact graph.
Developing and packaging our LinnOS experiment so that it is easily repeatable for us and for others provided us with various insights on how experiments should be packaged. For example, for the experiments that are as long and comprehensive as LinnOS, stability and making cells idempotent is quite important. If an error occurs at an intermediate stage, the user might be forced to restart. All of the insights we accumulated over the duration of the project will be shared in a separate blog post.
LinnOS Packaged Experiment Link: https://www.chameleoncloud.org/experiment/share/15?s=409ab137f20e4cd38ae3dd4e0d4bfa7c
OSDI Paper and Presentation Link: https://www.usenix.org/conference/osdi20/presentation/hao
Authors' Background:
This summer, a team of students worked on an experiment that ultimately became part of the LinnOS paper that infers the SSD performance with the help of its built in light neural network architecture. The LinnOS paper, which utilizes Chameleon testbed to provide a public executable workflow, will be presented in OSDI ’20 and is available here.
Two of the students, Levent Toksoz and Mingzhe Hao, write about their experience in this Chameleon User Stories series. Toksoz is a recent graduate of the University of Chicago computer science masters program. He studied physics and math as an undergrad at the University of Michigan and is planning to apply to PhD programs in computer science. Hao is a Ph.D candidate of the UCARE group in the Department of Computer Science at the University of Chicago. His research interests include operating systems, storage systems, and distributed systems.


Pictured: Mingzhe Hao, Left, and Levent Toksoz, Right.
No comments