Dynamo and Chameleon Aid Weather Scientists
- Nov. 13, 2019 by
- Georgios Papadimitriou
This work was part of the first ever SCinet Technology Challenge at Supercomputing 2019 in Denver, CO.
The Dynamo team won two awards: "Most Diverse Resource Set" and "Most Original Technical Approach."
Read more about the Challenge and the awards.
Modern computational science depends on many complex, compute, and data-intensive applications operating on distributed datasets that originate from a variety of scientific instruments and data repositories. Two major challenges for these applications are: (1) the provisioning of compute resources and (2) the integration of data into the scientists’ workflow.
DyNamo and CASA
DyNamo [7] is a project funded under the NSF Campus Cyberinfrastructure program, which aims to enable high-performance, adaptive, and performance-isolated data-flows across a federation of distributed cloud resources (e.g, ExoGENI, Chameleon, OSG, XSEDE Jetstream) [1, 2, 3, 4] and community data repositories.
Advances in network hardware and software defined networks have enabled high-performance, dynamically-provisioned networks. This functionality has been implemented on the ExoGENI testbed (http://www.exogeni.net) [2], and in addition to “stitching” ExoGENI sites together, it can also “stitch” external resources to the testbed (e.g., NSF Chameleon Cloud [1]) using a network artifact called “stitchport” [7].
Dynamo relies on the stitching capabilities of ExoGENI and by using the Mobius platform [8], it facilitates the provisioning of appropriate compute and storage resources for observational science workflows from diverse, national-scale cyberinfrastructure (CI). Efforts to use, configure, and reconfigure resources are significantly simplified by this approach. Additionally, through integration with the Pegasus Workflow Management System [6], DyNamo offers automation and orchestration of data-driven workflows on the provisioned infrastructure.
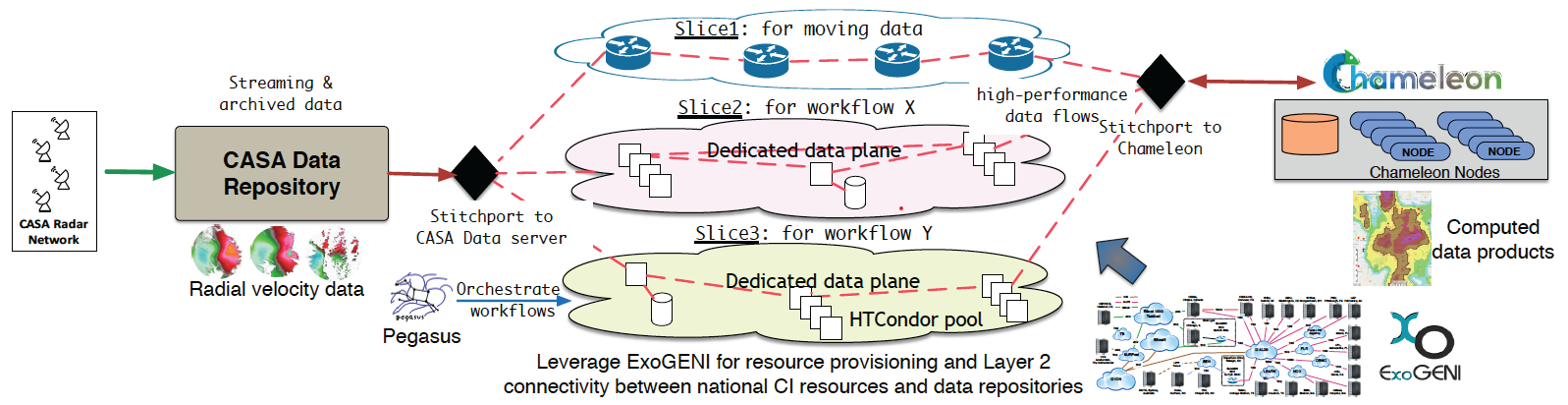
The NSF Engineering Research Center for Collaborative and Adaptive Sensing of the Atmosphere (CASA) [5] aims to improve our ability to observe, understand, predict, and respond to hazardous weather events. Because of its data movement challenges and its need to elastically scale resources on demand, CASA is one of many applications that stands to benefit from the DyNamo project. Moment data from a network of seven weather radars located in Dallas/Fort Worth (DFW) flow continuously to CASA’s data repository, triggering new processing tasks on the arrival of new data. With increase in severity of the weather comes increased processing times (severe weather often means significantly more data to process). Thus, additional resources have to be provisioned dynamically to assure that the processing is not delayed and warning and forecast information can be provided on time.
CASA Workflows
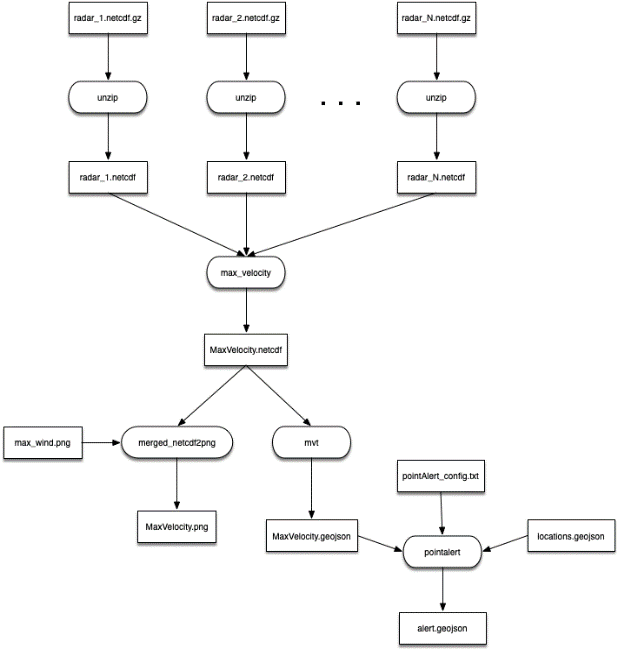
The Wind Speed pipeline (Figure 1) ingests radar moment data on radial velocity, but other variables are collected for noise reduction purposes as well. The first step in the process is the merging of an arbitrary number of individual radar data files. The wind speed algorithm attempts to create a grid of the maximum observed velocity, corrected for the height of the observation. The output is a single grid representing the estimate of the wind speed near the ground (Figure 2).
 |
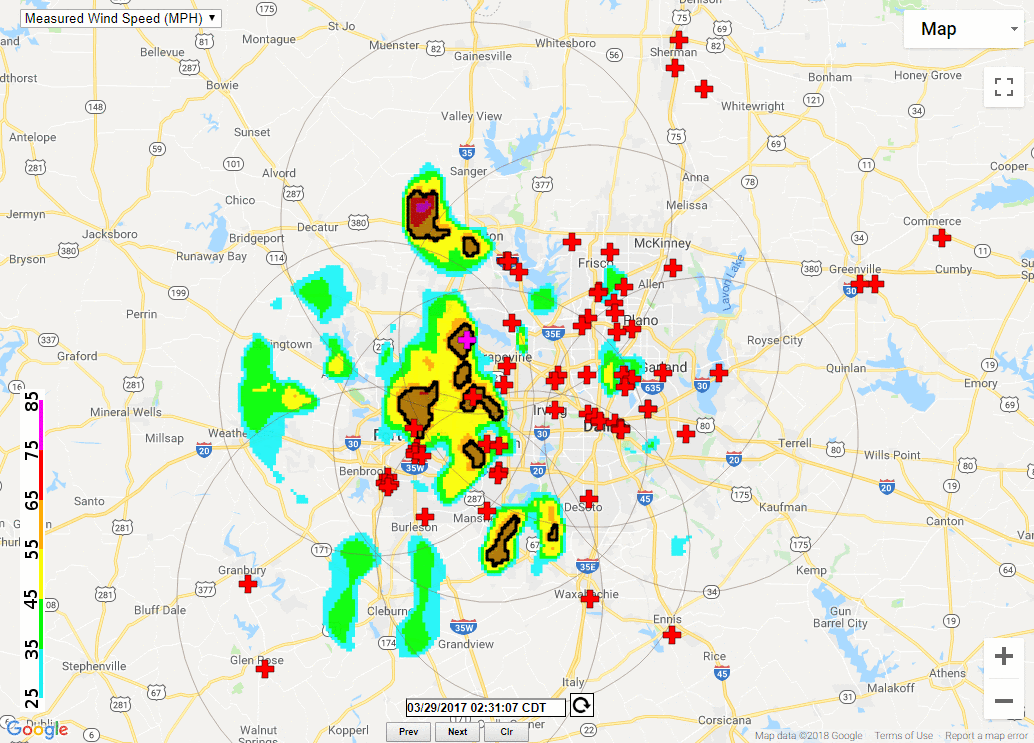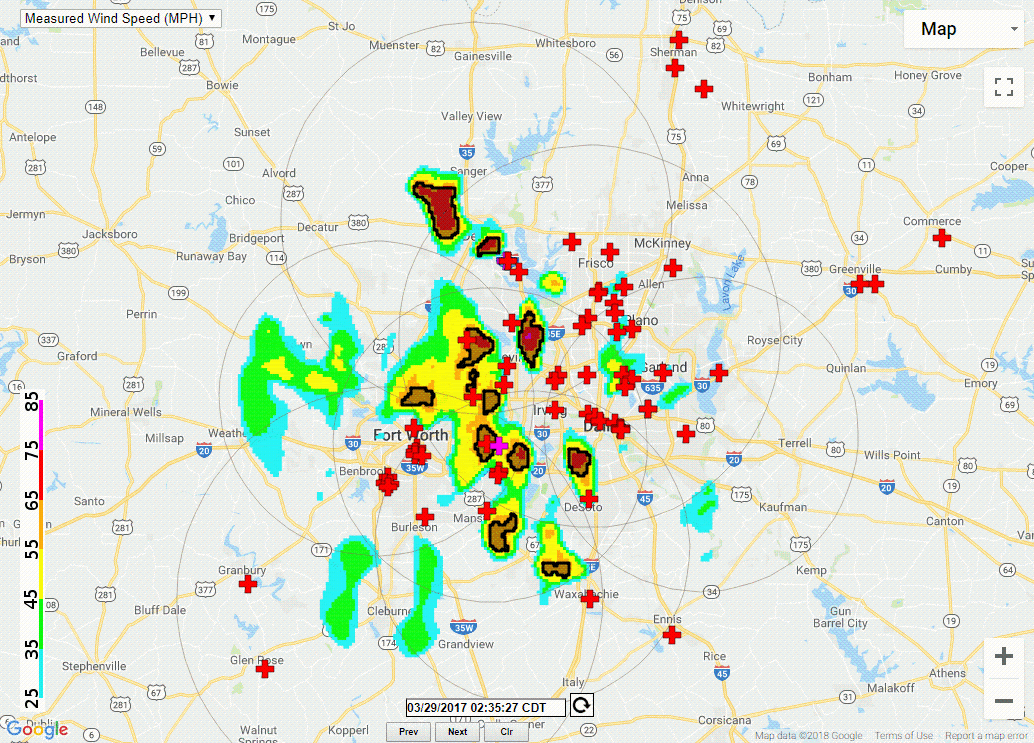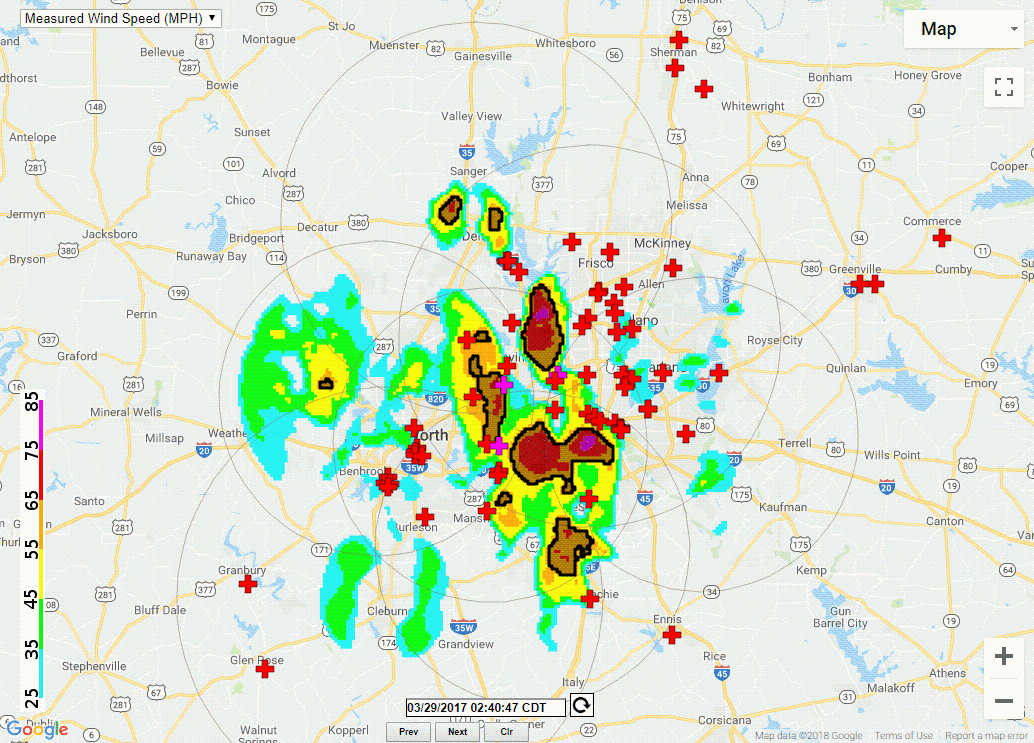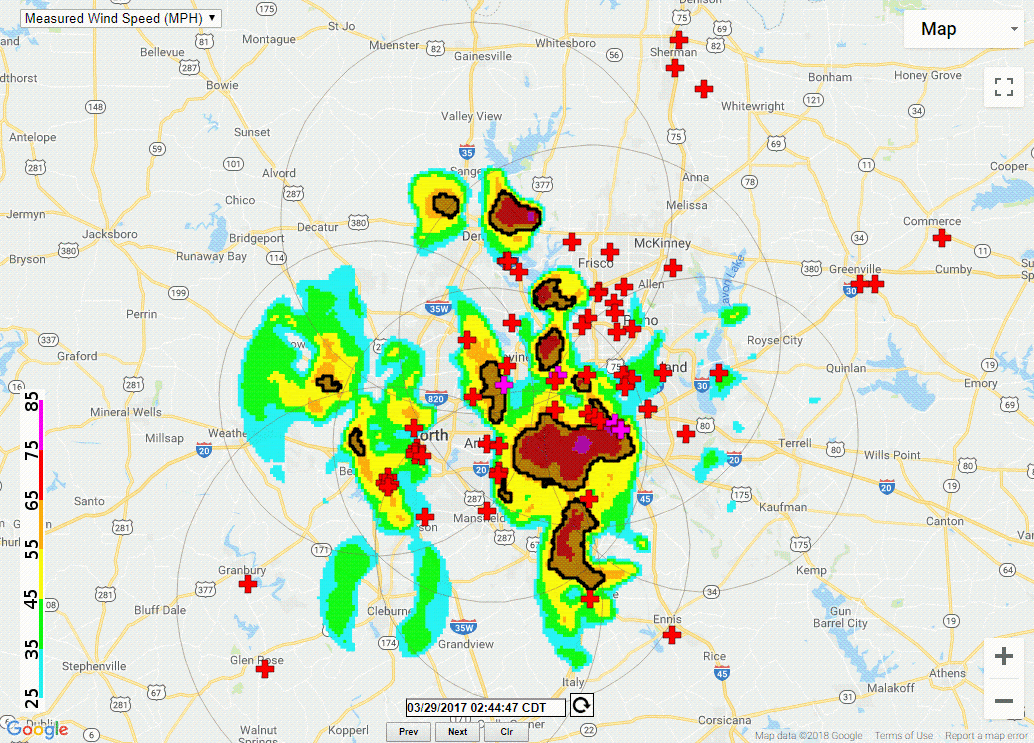 |
| Figure 1 | Figure 2 |
The Nowcast pipeline (Figure 3) ingests asynchronous individual radar data that have previously been combined into a merged grid. These gridded data are accumulated over time for a certain initialization period and then used as input to the nowcast algorithm. In its current version, the algorithm is processing data every minute and produces a series of gridded reflectivity data, where each grid corresponds to the projected conditions of each minute within the span of the next 30 minutes into the future. An example of the calculated reflectivity is presented in Figure 4.
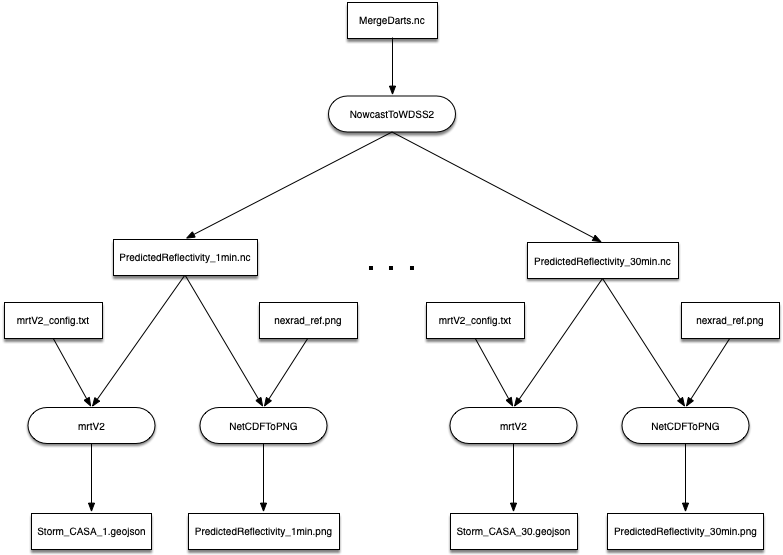 |
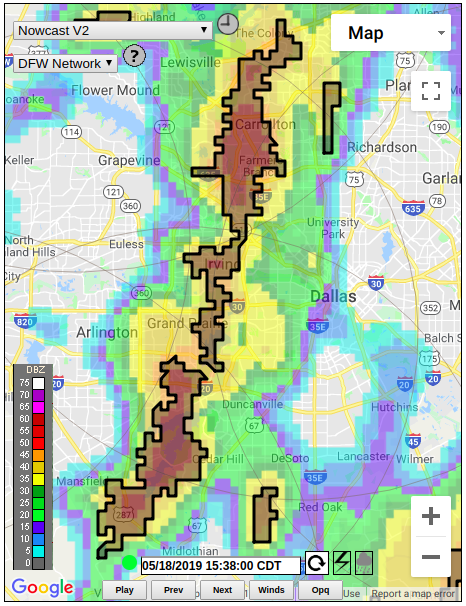 |
| Figure 3 | Figure 4 |
Dynamo and Chameleon
Chameleon is playing a key role in CASA’s workflow executions. Weather is changing constantly and as a result computation requirements change too. By taking advantage of Chameleon's direct stitching capabilities to ExoGENI [9], we can reliably connect Chameleon resources with CASA’s data repositories and scale up the available computing resources for its workflow executions, as seen in Figure 5. Due to the more powerful hardware available on Chameleon, CASA can scale up its computations faster than just using ExoGENI, by acquiring fewer physical nodes. However, this has the side effect of creating IO pressure on the Chameleon nodes, since multiple (over 24) tasks are getting executed simultaneously on the same node, and all of them have to stage-in, stage-out, read and write data. To mitigate any IO bottlenecks observed, CASA is using Storage node appliances to share data between the Chameleon workers, prefers nodes with SSDs (if available) and uses the shared network between TACC and the University of Chicago, to connect chameleon resources between them.
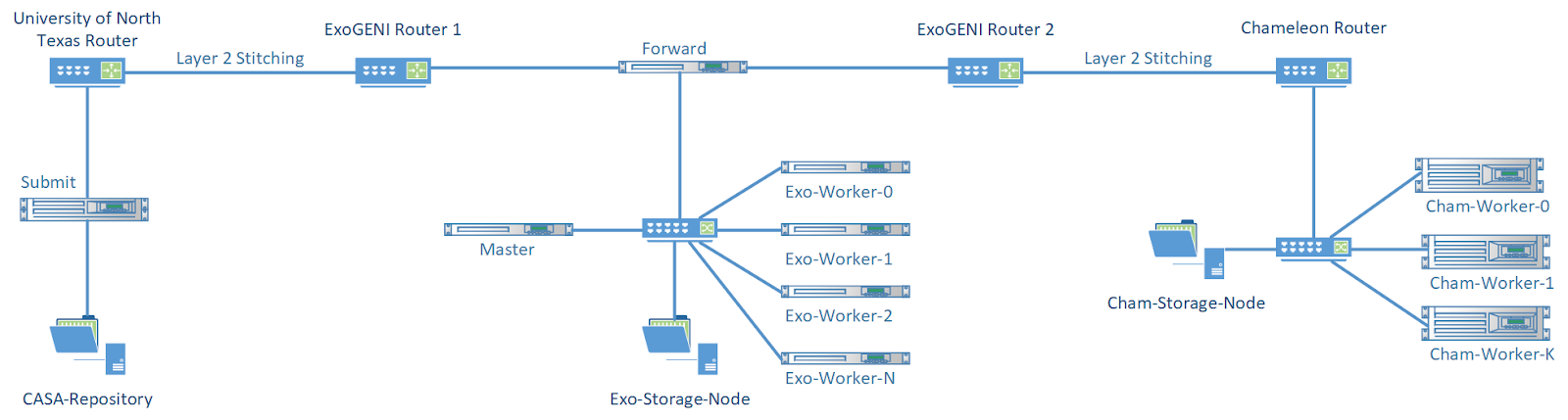 |
| Figure 5 |
Acknowledgements: DyNamo is supported by the National Science Foundation, award number #1826997.
References
[1] NSF Chameleon Cloud. https://chameleoncloud.org/
[2] I. Baldin, J. Chase, Y. Xin, A. Mandal, P. Ruth, C. Castillo, V. Orlikowski, C. Heermann, J. Mills. “ExoGENI: A Multi-Domain Infrastructure-as-a-Service Testbed.” The GENI Book, pp. 279--315, 2016.
[3] R. Pordes, D. Petravick, B. Kramer, D. Olson, M. Livny, A. Roy, P. Avery, K. Blackburn, T. Wenaus, F. Wurthwein, I. Foster, R. Gardner, M. Wilde, A. Blatecky, J. McGee, R. Quick, The open science grid, Journal of Physics:
Conference Series 78 (2007) 012057. doi:10.1088/1742-6596/78/1/012057. URL https://doi.org/10.1088%2F1742-6596%2F78%2F1% 2F012057
[4] J. Towns, T. Cockerill, M. Dahan, I. Foster, K. Gaither, A. Grimshaw, V. Hazlewood, S. Lathrop, D. Lifka, G. D. Peterson, R. Roskies, J. Scott, N. Wilkins-Diehr, Xsede: Accelerating scientific discovery, Computing in Science & Engineering 16 (05) (2014) 62–74. doi:10.1109/MCSE. 2014.80.
[5] B. Philips, D. Pepyne, D. Westbrook, E. Bass, J. Brotzge, W. Diaz, K. Kloesel, J. Kurose, D. McLaughlin, H. Rodriguez, and M. Zink. “Integrating End User Needs into System Design and Operation: The Center for Collaborative Adaptive Sensing of the Atmosphere (CASA).” In Proceedings of Applied Climatol., American Meteorological Society Annual Meeting, San Antonio, TX, USA, 2007.
[6] E. Deelman, K. Vahi, G. Juve, M. Rynge, S. Callaghan, P. J. Maechling, R. Mayani, W. Chen, R. Ferreira da Silva, M. Livny, and K. Wenger, “Pegasus: a workflow management system for science automation.” Future Generation Computer Systems, vol. 46, pp. 17–35, 2015.
[7] E. Lyons, G. Papadimitriou, C. Wang, K. Thareja, P. Ruth, J. J. Villalobos, I. Rodero, E. Deelman, M. Zink, and A. Mandal, “Toward a Dynamic Network-centric Distributed Cloud Platform for Scientific Workflows: A Case Study for Adaptive Weather Sensing,” in 15th eScience Conference, 2019.
[8] Mobius. https://github.com/RENCI-NRIG/Mobius
[9] Chameleon Direct Stitching. https://www.chameleoncloud.org/blog/2019/06/21/isolating-wide-area-networking-and-distributed-computing-experiments/
No comments